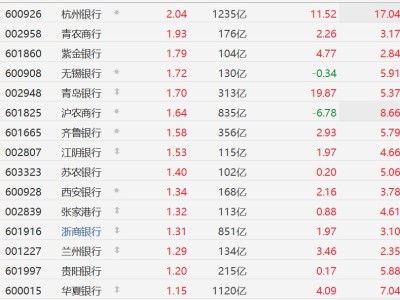
據科技媒體報道,英偉達近日宣布了一項重大戰略決策:未來五年將投入260億美元用于開發開源人工智能模型。這一舉措被業界視為其從傳統芯片制造商向頂尖AI實驗室轉型的關鍵信號,標志著這家硬件巨頭正式加入全球AI基礎模型競爭行列。
與傳統開源模式不同,英偉達選擇"開放權重"的技術路線——公開模型參數權重但保留部分許可權限。這種中間策略既區別于OpenAI的完全封閉模式,也不同于meta旗下Llama系列的徹底開源。分析指出,這種模式既能滿足企業用戶對模型透明度和可定制化的需求,又能通過硬件優化形成技術壁壘。
資金分配顯示,這筆巨額投資將覆蓋模型研發、算力基礎設施、人才儲備和生態建設四大領域。作為對比,OpenAI訓練GPT-4的成本約為30億美元。英偉達憑借自主掌控的超級計算資源和過去兩年秘密組建的研發團隊,計劃同時推進多個前沿大模型項目。公司內部文件顯示,首批模型預計在2026年底至2027年初面世。
金融領域測算表明,若英偉達在保持硬件市場主導地位的同時,能占據基礎模型市場10%的份額,三年內有望實現每年500億美元的額外收入。這一預測基于其硬件與軟件的協同效應——自研模型將深度適配自家GPU架構,形成"芯片-算法-應用"的閉環生態。
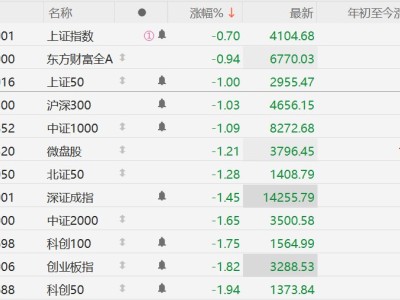
當前行業格局呈現明顯分化:美國頭部企業如OpenAI、Anthropic和谷歌均采用閉源策略,僅提供云端API訪問;meta雖堅持開源路線,但近期暗示可能調整策略。與此形成對比的是,中國科技公司如DeepSeek和阿里巴巴通過完全開源策略,在全球開發者社區贏得廣泛支持。英偉達的入局被視為對既有格局的重大挑戰。
公司應用深度學習研究副總裁Bryan Catanzaro公開表示,推動開源生態發展符合企業核心利益。這種立場與其硬件業務形成戰略協同——模型開發過程中產生的計算需求,將直接轉化為對自家GPU產品的采購訂單。據悉,英偉達近期已完成一個擁有5500億參數的超大模型預訓練,創下行業新紀錄。
企業生成式AI軟件副總裁Kari Briski透露,前沿模型研發不僅是技術探索,更是對存儲、網絡和超算中心的系統性壓力測試。這些實驗數據將為下一代硬件架構設計提供關鍵參數,形成"以軟促硬"的研發閉環。這種模式已被證實能有效縮短產品迭代周期,鞏固技術領先地位。