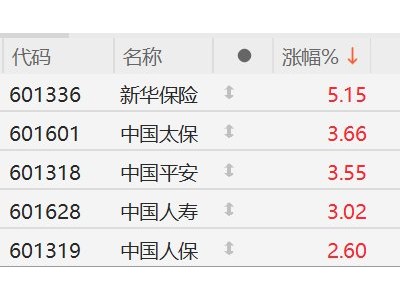
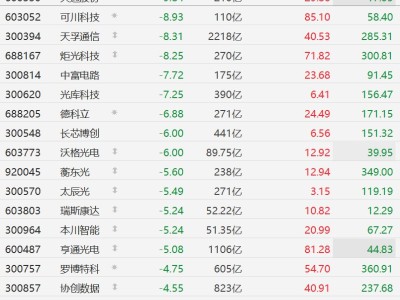
在人工智能技術持續突破的背景下,英偉達在近日舉辦的GTC主題演講中公布了一項重要技術進展:通過整合2025年從Groq收購的知識產權,公司正在為Rubin平臺注入全新算力。這項創新的核心是一款名為Groq 3 LPU的推理加速器芯片,其設計理念突破了傳統AI加速器的內存架構限制。
與主流AI加速器依賴高帶寬內存(HBM)的方案不同,Groq 3 LPU采用500MB的靜態隨機存取存儲器(SRAM)作為核心存儲單元。這種常用于CPU/GPU高速緩存的存儲技術,在單個芯片上實現了150TB/s的驚人帶寬,相較HBM4的22TB/s帶寬提升近7倍。盡管288GB的HBM4容量遠超SRAM,但后者在處理帶寬敏感型AI解碼任務時展現出顯著優勢,特別適用于需要實時交互的生成式AI場景。
英偉達的工程團隊將這種技術優勢轉化為系統級解決方案,推出了包含256個Groq 3 LPU的Groq 3 LPX機架。該系統通過專用擴展接口實現640TB/s的內部互聯帶寬,在128GB總SRAM容量的配置下,可提供高達40PB/s的推理加速能力。這種架構設計使得AI模型在處理萬億參數時,仍能保持數百萬token上下文窗口的實時交互性能。
超大規模計算副總裁Ian Buck特別強調了該技術對多智能體系統的變革性影響。在傳統架構中,AI代理間的通信吞吐量被限制在每秒100個token,而Rubin與Groq LPU的組合可將這一指標提升至1500個token/秒以上。這種數量級的提升,使得AI系統能夠擺脫人類交互的節奏限制,真正實現智能體間的自主高效協作。
技術白皮書顯示,這種架構創新源于對AI工作負載特性的深度理解。在需要處理數十億參數的生成式模型中,約70%的計算資源消耗在內存訪問環節。Groq 3 LPU通過將存儲單元與計算核心緊密耦合,將內存延遲降低至傳統架構的1/20,同時通過獨特的數據流架構避免了HBM架構中常見的帶寬爭用問題。
行業分析師指出,這項技術突破可能重塑AI基礎設施的競爭格局。特別是在需要處理超長上下文窗口的對話系統、多智能體協作平臺等場景,英偉達的新方案展現出顯著的性能優勢。隨著生成式AI從文本生成向復雜決策系統演進,這種低延遲、高吞吐的推理架構或將成為新一代AI基礎設施的標準配置。