在NVIDIA GTC 2026大會上,理想汽車基座模型負責人詹錕以《MindVLA-o1:開啟全能范式——下一代統一視覺-語言-動作自動駕駛大模型探索》為主題發表演講,正式發布新一代自動駕駛基礎模型MindVLA-o1。這一突破性成果標志著自動駕駛技術向更高效、更智能的方向邁出關鍵一步。
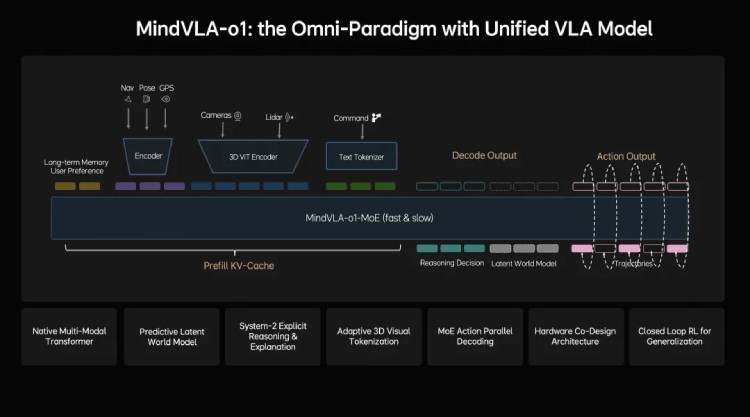
MindVLA-o1的核心優勢在于五大技術創新:3D空間理解技術讓車輛具備更精準的環境感知能力;多模態思考機制實現視覺、語言與動作的深度融合;統一行為生成框架確保決策的一致性與高效性;閉環強化學習體系支持模型持續自我優化;軟硬件協同設計則大幅提升了部署效率。這些技術共同構建起一個完整的AI閉環,使自動駕駛系統能夠"看得更遠、想得更深、行得更穩、進化更快、部署更高效"。
詹錕在演講中特別強調,MindVLA-o1采用原生多模態MoE Transformer架構,這是面向物理世界智能設計的專用模型。該架構突破了傳統自動駕駛模型的局限,不僅實現了感知、理解、行動的有機統一,更通過持續優化機制構建起自我進化的能力。這種設計理念使得同一套VLA模型既能應用于車輛控制,也可擴展至機器人等物理系統,為通用人工智能的發展開辟了新路徑。
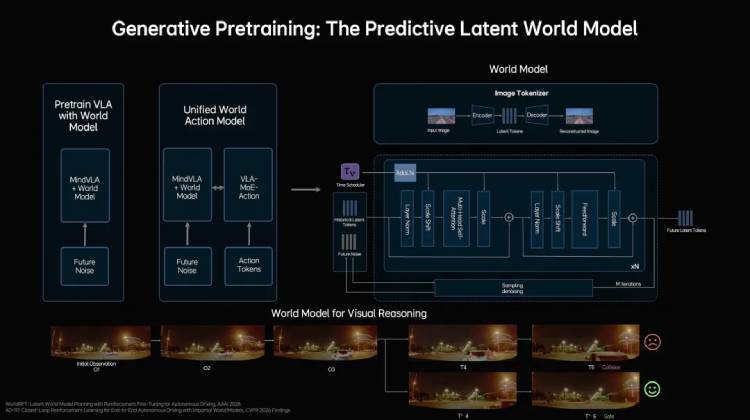
回顧發展歷程,理想汽車自2021年啟動輔助駕駛自研項目以來,始終保持技術迭代速度:2024年實現端到端+VLM雙系統架構的量產交付;2025年推出VLA司機大模型并全量推送至AD Max用戶,月使用率達到80%。這些積累為MindVLA-o1的研發奠定了堅實基礎。新模型的問世,不僅代表著自動駕駛技術的重大突破,更預示著物理AI時代的全面來臨——自動駕駛僅是這個宏大圖景的起點。