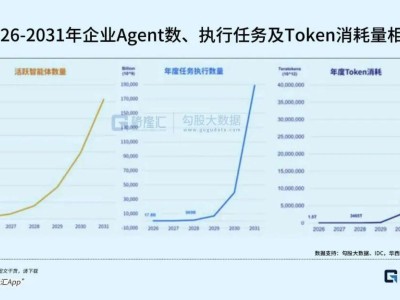
大型語言模型在處理長對話時,常面臨內存不足的瓶頸,這一問題不僅制約模型性能,還顯著增加了企業部署AI的硬件成本。NVIDIA研究人員近期提出一項名為KVTC(KV快取轉換編碼)的突破性技術,通過壓縮模型對話歷史所需的KV緩存,將內存占用最高降低20倍,同時實現首次回應生成速度提升8倍,且無需修改現有模型架構。
KV緩存作為模型的“短期記憶”,在對話處理中扮演關鍵角色。當模型與用戶交互時,會將對話中的關鍵信息(Key和Value)存儲為緩存,避免重復計算整段對話,從而提升響應效率。然而,隨著對話長度增加,緩存數據可能膨脹至數GB,占用大量GPU內存,反而導致計算效率下降。NVIDIA資深深度學習工程師指出,模型推理的性能瓶頸往往不在算力,而在于GPU內存的有限性——傳統方法需將閑置緩存轉移至CPU或硬盤,引發數據傳輸延遲和額外成本。
KVTC技術的核心創新在于借鑒JPEG圖像壓縮的思路,通過“主成分分析、自適應量化、熵編碼”三步流程,高效壓縮KV緩存。與傳統壓縮方法不同,該技術針對緩存數據高度相關的特性,在保留關鍵信息的同時剔除冗余內容,且支持分塊、逐層解壓,確保模型實時響應不受影響。實驗數據顯示,在參數量從15億到700億的模型(包括Llama 3系列、R1-Qwen 2.5等)中,KVTC即使將內存壓縮20倍,模型準確率損失仍低于1%,而傳統方法僅壓縮5倍便會出現顯著性能下降。
以H100 GPU處理8000個Token的提示為例,未使用KVTC時模型需3秒生成首個回應,啟用后僅需380毫秒,速度提升達8倍。這一特性使其尤其適用于編程助手、迭代式推理等長對話場景,而在短對話中壓縮效果相對有限。技術團隊強調,KVTC采用“非侵入式”設計,企業無需調整模型代碼即可快速部署,進一步降低了應用門檻。
目前,NVIDIA正推動KVTC與主流開源推理引擎的兼容,計劃將其整合至Dynamo框架的KV塊管理器中,以支持vLLM等工具的無縫調用。隨著大型語言模型對話能力的持續增強,標準化壓縮技術或將成為降低AI部署成本的關鍵路徑,為更廣泛的行業應用提供技術支撐。