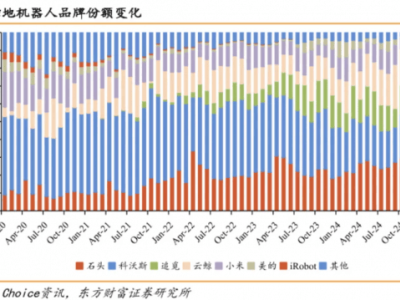
在人工智能競爭格局中,數據要素正成為決定勝負的關鍵變量。上海市經濟和信息化委員會相關負責人在近期舉辦的開發者論壇上明確指出,當前行業已從算法競賽轉向數據資源爭奪,優質語料庫的構建能力直接決定模型性能上限。這一判斷在生物醫藥領域得到生動印證:某蛋白質研發機構通過采集馬里亞納海溝等極端環境微生物數據,結合人工智能算法優化,僅用數月便開發出耐堿性提升400%的蛋白質,成功應用于長效生長激素研發,使相關產品療效獲得突破性進展。
上海正通過系統性布局構建數據競爭優勢。當地已形成覆蓋具身智能、科學計算等垂直領域的多層次數據供給體系,建成全國首個貫通數據采集、清洗、標注、應用、評估全流程的公共服務平臺。創新推出的"數據券"機制有效降低中小企業獲取優質數據的門檻,目前平臺已鏈接超過600萬個物質實體數據和千萬級化學反應數據,這些經過智能體提取對齊的科研數據,為AI驅動的科研范式轉型提供關鍵支撐。
數據采集方式正在發生革命性變革。具身智能領域涌現出新型數據獲取模式,某科技企業通過讓研發人員穿戴輕量化設備在真實工作場景中采集第一視角數據,既避免了傳統遙操作的高成本,又確保了數據的高質量與可擴展性。這種"人類本體采集法"已形成標準化流程,采集效率較傳統方式提升3倍以上,為機器人訓練提供了海量真實場景數據。
針對科研數據分散、格式不統一等痛點,上海人工智能實驗室開發出智能文獻解析系統。該系統可自動識別化學論文中的反應條件、物質屬性等關鍵信息,經過標準化處理后形成結構化數據庫。目前數據庫已覆蓋全球80%的化學期刊文獻,為AI科學家提供了可直接調用的"數據原料庫",顯著縮短新藥研發周期。
面向不同創新主體的數據需求,上海推出升級版普惠計劃。新方案將服務范圍擴展至科學智能領域和微型創新企業,計劃到2027年底培育300個特色數據集,鏈接500個科研團隊。在當天舉行的簽約儀式上,多家科研機構與科技企業達成數據共建協議,共同推進科研范式向"數據驅動+模型驗證"的深度融合模式轉型。同步啟動的語料創新榜單評選,將挖掘更多具有產業轉化價值的數據應用案例。