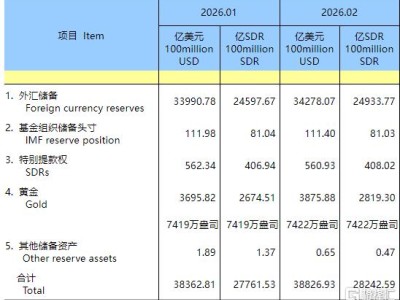
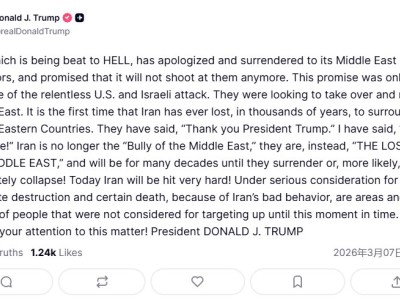
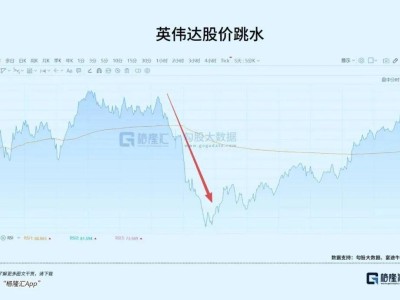
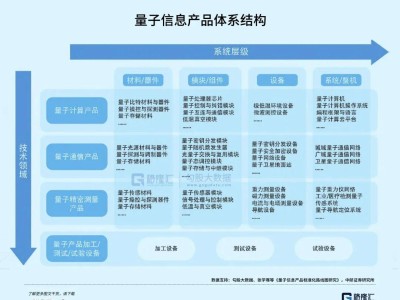
一款名為Scrapling的數據采集工具近日在開發者社區引發廣泛關注,其憑借突破性技術成為網絡爬蟲領域的新寵。這款工具通過創新機制解決了傳統爬蟲面臨的兩大核心難題——反爬蟲攔截與網頁結構動態變化,為自動化數據采集提供了全新解決方案。
在應對反爬蟲機制方面,Scrapling搭載的StealthyFetcher模塊展現出強大實力。該模塊通過模擬最新瀏覽器指紋和用戶操作行為,能夠繞過包括圖形驗證、行為檢測在內的多重防護機制。這種"隱身"技術使采集過程無需人工干預即可持續進行,特別適合需要長期穩定運行的自動化任務。
面對網頁頻繁改版帶來的挑戰,工具開發者設計了獨特的自適應解析算法。當目標網站調整HTML結構時,系統會通過元素相似度比對自動追蹤關鍵數據位置,確保采集準確性不受影響。這種智能追蹤能力使任務中斷率降低90%以上,顯著提升了數據采集的穩定性。
在數據處理環節,MCP模式成為降低使用成本的關鍵創新。該模式可自動剔除網頁中的廣告、冗余代碼等非核心內容,將有效數據體積壓縮60%以上。這種預處理機制不僅減少了后續AI模型處理的計算量,更直接降低了API調用成本,特別適合大規模數據采集場景。
工具的輕量化設計同樣引人注目。系統內存占用控制在200MB以內,支持在入門級服務器甚至舊筆記本上穩定運行。斷點續傳功能確保網絡中斷或系統重啟后,采集任務可從暫停位置繼續執行,避免了重復勞動。這些特性使其成為個人開發者和小型團隊的理想選擇。
操作便捷性是該工具的另一大亮點。開發者提供了完整的命令行接口,用戶無需掌握Python編程即可通過簡單指令完成復雜采集任務。配套的詳細文檔和示例代碼進一步降低了使用門檻,使得非技術背景人員也能快速上手。
據開發者透露,Scrapling正在與某知名自動化平臺進行深度集成,未來將作為插件形式直接嵌入該平臺生態系統。這項合作預計將使數百萬用戶獲得更強大的網絡數據采集能力,推動自動化流程向更智能的方向發展。目前項目在GitHub已獲得超過2.3萬個星標,連續多日占據趨勢榜首位。