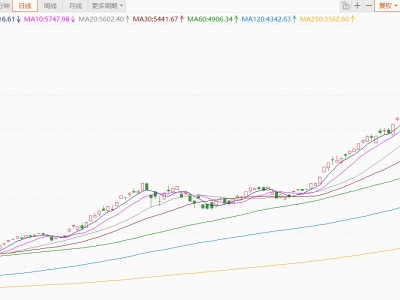
在人工智能視覺生成領域,擴散模型憑借其卓越的高保真數(shù)據生成能力,已成為圖像合成、視頻生成等跨模態(tài)任務的核心技術框架。然而,如何讓預訓練后的擴散模型高效適配具體應用場景,始終是制約技術落地的關鍵難題。近期,一項發(fā)表于國際頂級學術會議的研究提出創(chuàng)新解決方案,通過設計遞歸似然比優(yōu)化器,為擴散模型后訓練開辟了兼顧效率與性能的新路徑。
當前擴散模型的后訓練方法主要依賴強化學習與截斷反向傳播兩類技術路線,但均存在顯著缺陷。截斷反向傳播通過終止部分梯度計算降低內存消耗,卻導致梯度估計出現(xiàn)結構性偏差,嚴重時模型會崩潰并生成純噪聲;強化學習雖能控制內存需求,但梯度估計方差過高,樣本效率低下且訓練收斂緩慢。實驗數(shù)據顯示,使用完整反向傳播訓練Stable Diffusion 1.4模型僅需50個時間步就消耗約1TB GPU內存,而現(xiàn)有優(yōu)化方法難以在訓練穩(wěn)定性與生成質量間取得平衡。
研究團隊提出的遞歸似然比優(yōu)化器,通過重構擴散鏈計算圖實現(xiàn)無偏且低方差的梯度估計。該技術包含三大核心模塊:一階估計模塊在初始時間步直接反向傳播獎勵模型,充分利用結構信息避免精度損失;半階優(yōu)化模塊引入長度可變的局部子鏈,通過隨機選擇起始位置捕捉多尺度視覺特征;零階估計模塊對剩余時間步采用參數(shù)擾動策略,確保無偏性同時降低計算開銷。這種半階梯度估計范式巧妙平衡了計算成本與優(yōu)化效果。
局部子鏈長度h作為關鍵調控參數(shù),直接影響內存消耗與梯度方差的關系。研究團隊將h的取值問題轉化為帶內存約束的方差最小化優(yōu)化,推導出理論最優(yōu)解析解。實驗表明,在30-40GB主流GPU內存環(huán)境下,h=2時既能捕捉擴散鏈關鍵尺度信息,又可將整體方差降至飽和區(qū)間。當h增至3或4時,單步訓練時間呈指數(shù)級增長,但獎勵分數(shù)提升幅度不足5%,驗證了該參數(shù)選擇的工程合理性。
理論分析證實,遞歸似然比估計器具有無偏性,并給出了方差邊界與收斂速率保證。相較于傳統(tǒng)方法,該技術既解決了截斷反向傳播的偏差問題,又克服了強化學習的高方差缺陷,在計算效率與優(yōu)化性能間實現(xiàn)最優(yōu)平衡。實驗數(shù)據顯示,在文本到圖像生成任務中,基于Stable Diffusion 1.4的實驗使ImageReward分數(shù)從32.90提升至76.55,較主流方法提升幅度達14%-47%。
在文本到視頻生成任務的VBench基準測試中,該技術展現(xiàn)出顯著優(yōu)勢。在主體一致性、運動流暢度等6項核心指標上,加權平均分達84.63,超越VideoCrafter、Pika等開源及商業(yè)模型。特別在動態(tài)程度指標上取得70.69分,較次優(yōu)方案提升5.6%。研究團隊還開發(fā)了擴散思維鏈提示詞技術,通過分解原始提示詞為多尺度指令,使半階子鏈能精準定位生成缺陷的尺度特征,在手部生成等細粒度任務中實現(xiàn)突破性進展。