在NVIDIA GTC 2026大會(huì)上,理想汽車(chē)基座模型負(fù)責(zé)人詹錕發(fā)表了題為《MindVLA-o1:開(kāi)啟全能范式 —— 下一代統(tǒng)一視覺(jué)-語(yǔ)言-動(dòng)作自動(dòng)駕駛大模型探索》的主題演講,正式推出其新一代自動(dòng)駕駛基礎(chǔ)模型MindVLA-o1。這一突破性成果標(biāo)志著自動(dòng)駕駛技術(shù)向物理世界智能邁出了重要一步。
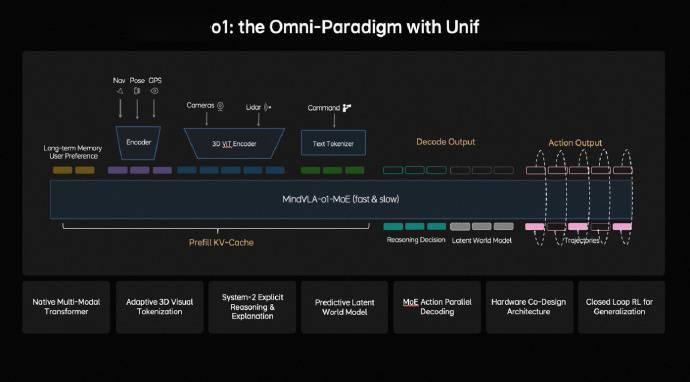
MindVLA-o1的核心創(chuàng)新體現(xiàn)在五大技術(shù)維度。在3D空間理解方面,該模型突破了傳統(tǒng)二維圖像處理的局限,通過(guò)融合攝像頭與激光雷達(dá)數(shù)據(jù),構(gòu)建出三維編碼器系統(tǒng)。這一技術(shù)使車(chē)輛能夠精準(zhǔn)感知物體的深度、距離及運(yùn)動(dòng)軌跡,實(shí)現(xiàn)與人類(lèi)駕駛員相似的三維空間認(rèn)知能力,為復(fù)雜路況下的決策提供可靠依據(jù)。
多模態(tài)思考能力是該模型的另一大亮點(diǎn)。基于隱世界模型架構(gòu),MindVLA-o1具備"預(yù)演未來(lái)"的獨(dú)特功能。系統(tǒng)不僅能實(shí)時(shí)分析當(dāng)前場(chǎng)景,還能在虛擬空間中模擬未來(lái)數(shù)秒可能發(fā)生的多種情況,從而提前制定最優(yōu)應(yīng)對(duì)策略。這種前瞻性思維模式顯著提升了自動(dòng)駕駛系統(tǒng)的決策質(zhì)量與安全性。
在行為生成層面,VLA-MoE架構(gòu)的引入實(shí)現(xiàn)了行駛軌跡的統(tǒng)一優(yōu)化。系統(tǒng)配備的"動(dòng)作專(zhuān)家"模塊可同步生成所有軌跡點(diǎn),并通過(guò)類(lèi)似信號(hào)去噪的優(yōu)化算法,確保車(chē)輛運(yùn)動(dòng)既符合物理規(guī)律又保持平穩(wěn)流暢。這種設(shè)計(jì)有效解決了傳統(tǒng)方案中軌跡規(guī)劃與執(zhí)行脫節(jié)的問(wèn)題。
訓(xùn)練效率的革命性提升得益于閉環(huán)強(qiáng)化學(xué)習(xí)技術(shù)。理想汽車(chē)構(gòu)建的世界模擬器為模型提供了虛擬訓(xùn)練場(chǎng)域,使系統(tǒng)能夠在虛擬環(huán)境中進(jìn)行海量場(chǎng)景練習(xí)與策略?xún)?yōu)化。這種訓(xùn)練方式不僅大幅降低了現(xiàn)實(shí)道路測(cè)試的成本與風(fēng)險(xiǎn),更將模型迭代速度提升了數(shù)個(gè)量級(jí)。
軟硬件協(xié)同設(shè)計(jì)突破了模型部署的技術(shù)瓶頸。通過(guò)精確平衡模型精度與硬件延遲,研發(fā)團(tuán)隊(duì)將架構(gòu)設(shè)計(jì)周期從數(shù)月壓縮至數(shù)天。這種高效設(shè)計(jì)確保了復(fù)雜大模型能夠在車(chē)端芯片上穩(wěn)定運(yùn)行,為自動(dòng)駕駛系統(tǒng)的量產(chǎn)落地掃清了關(guān)鍵障礙。