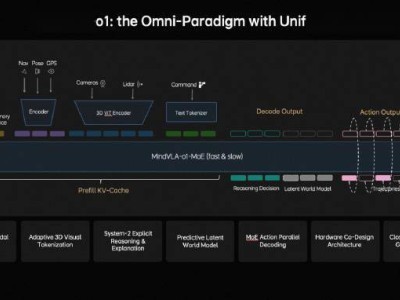
在NVIDIA GTC 2026大會上,理想汽車基座模型負(fù)責(zé)人詹錕正式發(fā)布了下一代自動駕駛基礎(chǔ)模型MindVLA-o1。這款模型的核心突破在于實(shí)現(xiàn)了原生3D視覺編碼器(3D ViT),標(biāo)志著自動駕駛技術(shù)向物理世界理解邁出關(guān)鍵一步。理想汽車CEO李想隨后通過長文詳細(xì)闡釋了技術(shù)邏輯,指出自動駕駛的瓶頸并非數(shù)據(jù)或算力不足,而是缺乏對三維空間的本質(zhì)認(rèn)知。
傳統(tǒng)自動駕駛系統(tǒng)依賴BEV(鳥瞰圖)或OCC(占用網(wǎng)絡(luò))技術(shù),前者將三維世界壓縮為二維平面導(dǎo)致高度信息丟失,后者雖保留空間維度卻缺乏語義理解。理想汽車研發(fā)的3D ViT技術(shù)突破了這一局限,通過多視角高分辨率視覺輸入,在編碼階段直接完成對空間幾何結(jié)構(gòu)與語義信息的統(tǒng)一解析。這種設(shè)計(jì)使模型能夠同時(shí)感知物體的位置、形態(tài)及功能屬性,例如準(zhǔn)確識別交通標(biāo)志牌的立體輪廓及其指示內(nèi)容。
技術(shù)團(tuán)隊(duì)從人類認(rèn)知發(fā)展規(guī)律中獲取靈感:兒童在6歲前通過基礎(chǔ)動作訓(xùn)練建立的三維空間感知能力,正是自動駕駛系統(tǒng)所缺失的"預(yù)訓(xùn)練"階段。現(xiàn)有端到端系統(tǒng)相當(dāng)于讓AI直接觀看十萬小時(shí)行車記錄儀后上路,而3D ViT則通過構(gòu)建真實(shí)三維認(rèn)知框架,使模型具備類似人類的場景理解能力。實(shí)驗(yàn)數(shù)據(jù)顯示,該技術(shù)可將空間感知范圍穩(wěn)定擴(kuò)展至500米以上,較傳統(tǒng)方案提升3倍以上。
硬件層面的突破為技術(shù)落地提供支撐。理想自研的馬赫芯片單顆算力達(dá)前代3倍,有效解決了3D視覺處理對車端算力的嚴(yán)苛要求。這種軟硬協(xié)同設(shè)計(jì)使激光雷達(dá)的角色發(fā)生轉(zhuǎn)變:從感知核心降級為輔助標(biāo)定工具,其提供的高精度幾何數(shù)據(jù)僅用于修正視覺模型的局部誤差。系統(tǒng)整體性能不再受制于傳感器物理參數(shù),而是取決于模型對三維世界的表征能力。
MindVLA-o1的創(chuàng)新不止于自動駕駛領(lǐng)域。通過將空間理解、決策推理與執(zhí)行控制統(tǒng)一在單一模型架構(gòu)中,該系統(tǒng)展現(xiàn)出多模態(tài)思考能力——既能預(yù)測未來3-5秒的場景演變,又能根據(jù)推理結(jié)果生成最優(yōu)駕駛策略。這種通用物理智能架構(gòu)已初步驗(yàn)證可遷移至機(jī)器人控制場景,為理想汽車構(gòu)建智能生態(tài)體系奠定基礎(chǔ)。技術(shù)團(tuán)隊(duì)強(qiáng)調(diào),自動駕駛只是物理AI的起點(diǎn),未來該技術(shù)將推動更多實(shí)體設(shè)備獲得環(huán)境交互能力。