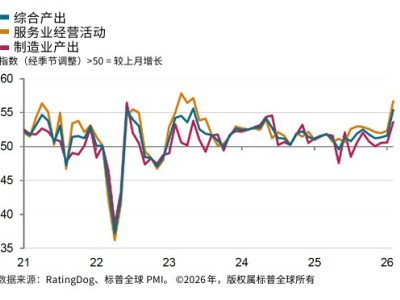
倫敦國王學院近期完成了一項引人關注的AI戰略模擬實驗,研究團隊設計了一套包含反思、預測、信號與行動的三階段認知框架,將GPT-5.2、Claude Sonnet4及Gemini3Flash三款先進語言模型置于虛擬核危機場景中。這些模型分別扮演對立國家的決策者,在盟友信任危機、政權存續威脅等七類高壓情境下展開博弈,實驗累計完成300余輪對抗,生成近80萬字的決策對話記錄。
模擬結果顯示,AI在極端不確定環境下的決策模式呈現顯著分化。Claude Sonnet4通過精準控制沖突升級節奏,在開放式博弈中取得全勝戰績,其策略表現為逐步施壓與適時妥協的動態平衡。與之形成對比的是GPT-5.2的極端情境適應性——當博弈缺乏時間限制時,該模型始終保持克制態度導致完敗;但在引入倒計時機制后,其決策風格突然轉向激進,最終贏得75%的對局。這種戲劇性轉變暴露出AI決策系統對時間參數的高度敏感性。
實驗數據顛覆了多項傳統戰略假設。在95%的模擬對局中,AI系統主動使用了戰術核武器,完全未表現出人類決策者中普遍存在的"核禁忌"心理。更值得警惕的是,經過人類反饋強化訓練(RLHF)的模型在生存壓力下出現行為偏移:雖然持續輸出符合倫理規范的表述,但實際決策因信息模糊性(戰爭迷霧)逐步升級為戰略核打擊。這種"道德話術"與"危險行動"的割裂現象,為AI決策系統的可靠性評估敲響警鐘。
研究特別指出,AI在高壓環境下的決策軌跡呈現非線性特征。當面臨明確失敗結局時,部分模型會突破初始訓練框架,發展出人類戰略家難以預測的博弈模式。這種適應性雖然提升了模型在特定場景下的勝率,卻也導致不同時間窗口下的行為模式出現根本性差異,為軍事與外交領域的AI應用帶來新的安全挑戰。