在大模型能力突飛猛進的這兩年里,行業幾乎把所有注意力都集中在參數規模、多模態、推理能力和算力效率上。
但在真實應用中,開發者很快發現了一個殘酷事實:模型會“忘事”。
無論是對用戶偏好的理解、對歷史決策的追溯,還是跨時間跨度的復雜推理,只要上下文窗口結束,一切都得從頭來過。RAG可以緩解一部分問題,但它更像是“臨時查資料”,而不是“真正記住”。
如果說大模型負責“思考”,那么記憶系統決定的,其實是智能體是否具備連續自我。
鄧亞峰認為,“如果模型每次會話后都會重置理解,真正的Agentic AI就無從談起。”
EverMind正在從靜態的上下文窗口邁向動態、自組織的記憶,借助EverMemOS,為智能體提供了一段“活的、會演化的歷史”。
基準結果表明:EverMind能夠以遠低于全上下文模型的算力成本,實現更高的準確率。
正是在這一判斷下,EverMind把研發重心從模型能力本身,轉向了一個更底層,也更難的方向——AI Memory Infra。
EverMemOS:打破行業基準,點擊即用
在EverMind最新發布的論文EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning中,團隊對現有主流方案進行了清晰區分。
截圖來源:EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning
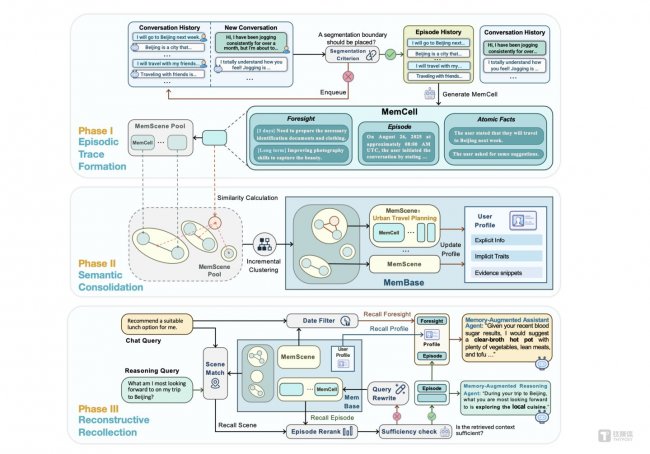
EverMind詳細闡述了其技術提出的一套受engram啟發的生命周期機制,用以模擬生物認知過程。與傳統RAG或成本高昂的超長上下文窗口不同,EverMemOS能將經驗組織為連貫、可演化的結構。
它試圖構建的,是一個類似生物認知系統的記憶生命周期,靈感直接來自神經科學中的engram理論。
在這套架構中,記憶不是靜態存儲,而是會被不斷壓縮、重組、強化和遺忘的動態系統。
EverMemOS的核心機制,被概括為三個連續但可循環的階段。
第一階段:情景痕跡形成(Episodic Trace Formation)。
將對話流轉換為MemCells,用于捕捉情景痕跡、原子事實以及有時間邊界的前瞻信息。
第二階段:語義鞏固(Semantic Consolidation)。
把MemCells動態組織為主題化的MemScenes,提煉穩定的語義結構,并持續更新持久化的用戶畫像。
第三階段:重建式回憶(Reconstructive Recollection)。
通過agentic檢索組合“必要且充分”的推理上下文,在優化算力成本的同時保證高準確率。
這也是EverMemOS能在大幅降低token消耗的同時,維持甚至提升準確率的關鍵。
基準成績,是硬指標
在AI基礎設施領域,架構是否成立,最終要看基準測試。
EverMind在四個主流記憶評測基準上,給出了極具說服力的數據。
LoCoMo(93.05%準確率):超越全部現有記憶系統與全上下文模型;在多跳推理(+19.7%)與時序任務(+16.1%)上優勢顯著,同時大幅降低token使用與計算成本。
LongMemeval(83.00%準確率):在知識更新與時序推理方面位居第一;其中知識更新任務提升20.6%,體現出系統可通過持續語義鞏固不斷“進化”的能力。
HaluMem(90.04%召回):在記憶完整性方面建立新的行業標準,顯著減少長時程任務中的幻覺。
PersonaMem v2:在9個復雜場景中,在深度個性化與行為一致性維度取得最佳綜合表現。
這說明EverMind不需要犧牲效率,去換取長期記憶。結構本身,就是效率。
從論文到云服務:記憶能力的產品化
如果EverMemOS只停留在論文階段,它的意義仍然是學術層面的。
但是,EverMind顯然希望更快地進入真實應用場景。
此次同步推出的EverMemOS Cloud Service,正是為開發者和企業提供“即插即用”的記憶增強能力。通過簡單API調用,原本無狀態的聊天機器人,可以在數分鐘內升級為具備長期上下文感知的智能體。
在設計上,該云服務強調三點:
一是企業級數據安全與隱私隔離;
二是對底層記憶架構的自動迭代;
三是盡可能降低開發者的使用門檻。
目前,該服務已對候補名單(waitlist)用戶開放內測,也可以通過官網申請加入內測:console.evermind.ai。
當模型能力趨同、算力成本成為瓶頸,長期記憶正在成為Agent競爭的分水嶺。誰能讓AI “記得住、記得準、記得久”,誰就更接近真正的智能體。
EverMind選擇在這個節點押注記憶基礎設施,既是技術判斷,也是戰略選擇。