在人工智能算力競爭日益激烈的當下,如何讓中國自主研發的算力系統高效運行于本土網絡環境,成為產業界關注的焦點。近日,中科曙光推出的首款原生無損RDMA高速網絡scaleFabric,為破解這一難題提供了創新方案。這款全棧自研的網絡架構,通過重構底層通信機制,實現了AI集群性能的突破性提升,標志著國產算力基礎設施邁入全新階段。
傳統AI集群建設中,網絡性能往往成為制約整體效率的關鍵瓶頸。以萬卡規模集群為例,其通信需求堪比超大型城市的交通系統,而現有技術方案存在明顯缺陷:基于以太網的RoCE方案需通過復雜流控機制模擬無損環境,導致部署周期長達數月且運維成本高昂;海外IB方案雖性能優異,但面臨供應鏈風險與成本壓力。這種技術困境,使得多數企業難以充分發揮算力潛力。
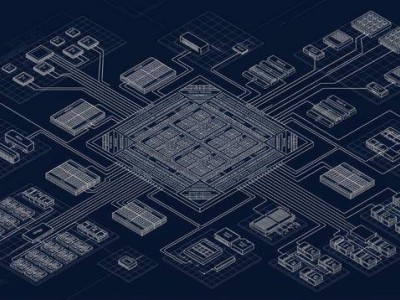
scaleFabric的創新之處在于其"原生無損"設計理念。該方案從物理層到協議棧實現全棧自主創新,采用112G PAM4高速Serdes技術,構建了包含交換芯片、網卡芯片及智能管理平臺的完整技術體系。其核心的信用流控機制,通過預先確認接收端緩沖區空間,從根本上消除了數據丟包風險。這種設計使網絡通信從"被動應對擁塞"轉變為"主動預防擁塞",為AI訓練提供了穩定可靠的通信保障。
在鄭州國家超算互聯網核心節點的實戰部署中,scaleFabric展現了驚人的效率優勢。三套萬卡集群僅用36小時即完成網絡調試,相比傳統RoCE方案數月的部署周期,效率提升達數十倍。這種突破源于其集中管控架構:子網管理系統可在3分鐘內自動完成全網拓撲發現與路由計算,實現"一鍵部署"。對于運維人員而言,系統提供的數字孿生可視化界面與智能故障診斷功能,將復雜網絡管理轉化為標準化操作流程。
成本效益分析顯示,scaleFabric在多個維度實現優化。通過高密度交換芯片設計,其組網密度較同類產品提升25%,使得同等規模集群所需硬件數量減少,綜合網絡成本降低約30%。更關鍵的是,其"即插即用"特性消除了對專業運維團隊的依賴,將隱性成本轉化為可量化的系統效能提升。實測數據顯示,在工業仿真等并行計算場景中,該方案可使算力利用率提升20%以上,達到國際主流產品性能水平的96%-105%。
這款國產網絡方案的突破性不僅體現在技術指標,更在于其開放的生態建設理念。中科曙光牽頭成立的"AIDC高速網絡工作組",已匯聚十余家軟硬件合作伙伴,共同推進場景化解決方案開發。scaleFabric原生兼容IB應用生態,支持PyTorch等主流框架無縫遷移,為科研機構與企業用戶提供了靈活的技術選擇。在中國科學院計算技術研究所的測試中,該方案在單QP通信性能等關鍵指標上達到國際領先水平,特別在國產CPU適配方面展現出獨特優勢。
當前,AI發展正從訓練階段向推理階段延伸,對智算基礎設施提出更高要求。科大訊飛在鄭州超算節點的實踐表明,scaleFabric支撐的單機柜640卡集成方案,可有效滿足超大規模智算需求。這種技術突破正在推動產業生態變革,隨著自主網絡標準的制定與優化,中國AI算力正逐步擺脫對單一技術路線的依賴,走出一條開放協作的自主發展道路。