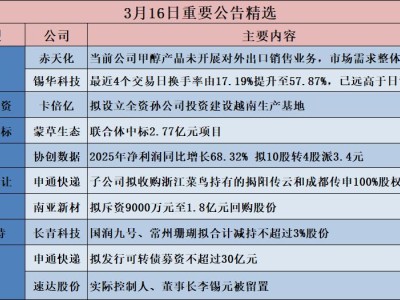
在2026年GTC大會(huì)上,英偉達(dá)宣布推出Vera Rubin AI平臺(tái),旨在全面推動(dòng)智能體AI(Agentic AI)的技術(shù)突破與應(yīng)用落地。這一平臺(tái)被視為英偉達(dá)史上最大規(guī)模基礎(chǔ)設(shè)施建設(shè)的起點(diǎn),覆蓋從大規(guī)模預(yù)訓(xùn)練到實(shí)時(shí)推理的完整AI生命周期。公司創(chuàng)始人兼首席執(zhí)行官黃仁勛強(qiáng)調(diào),Vera Rubin不僅是一次技術(shù)代際的飛躍,更標(biāo)志著英偉達(dá)在AI硬件領(lǐng)域的戰(zhàn)略升級(jí)。
Vera Rubin平臺(tái)的核心是全新設(shè)計(jì)的Vera CPU,其單顆芯片集成88個(gè)核心與144個(gè)線(xiàn)程,采用英偉達(dá)深度定制的Arm v9.2-A Olympus架構(gòu)。該架構(gòu)通過(guò)指令級(jí)并行度(IPC)的1.5倍提升,實(shí)現(xiàn)了計(jì)算效率的顯著突破。更引人注目的是其首發(fā)的“空間多線(xiàn)程”技術(shù),通過(guò)物理隔離流水線(xiàn)組件,使多個(gè)線(xiàn)程能夠在單核上并行運(yùn)行,徹底解決了傳統(tǒng)多線(xiàn)程技術(shù)中因資源排隊(duì)導(dǎo)致的算力損耗問(wèn)題。
在系統(tǒng)級(jí)架構(gòu)方面,新一代NVL72機(jī)架成為關(guān)鍵支撐。該機(jī)架通過(guò)NVLink 6技術(shù)連接72塊Rubin GPU與36塊Vera CPU,形成高效協(xié)同的計(jì)算集群。與上一代Blackwell平臺(tái)相比,NVL72在混合專(zhuān)家大模型(MoE)訓(xùn)練中僅需四分之一的GPU資源,同時(shí)將每瓦推理吞吐量提升至10倍,單Token成本降低至十分之一。這一突破使得大規(guī)模AI模型的訓(xùn)練與部署成本大幅下降,為智能體AI的廣泛應(yīng)用奠定了基礎(chǔ)。
針對(duì)智能體系統(tǒng)對(duì)低延遲和長(zhǎng)上下文處理的嚴(yán)苛需求,英偉達(dá)同步推出了Groq 3 LPX推理加速機(jī)架。該系統(tǒng)集成256個(gè)LPU處理器,與Vera Rubin平臺(tái)結(jié)合后,每兆瓦推理吞吐量最高可提升35倍。這一設(shè)計(jì)顯著優(yōu)化了實(shí)時(shí)交互場(chǎng)景下的響應(yīng)速度,為智能客服、自動(dòng)駕駛等應(yīng)用提供了更強(qiáng)大的硬件支持。
在數(shù)據(jù)存儲(chǔ)領(lǐng)域,全新BlueField-4 STX機(jī)架構(gòu)建了AI原生存儲(chǔ)架構(gòu)。通過(guò)引入DOCA Memos框架,該系統(tǒng)能夠高效處理大型語(yǔ)言模型生成的海量鍵值(KV)緩存數(shù)據(jù),在降低能耗的同時(shí)將推理吞吐量提升最高5倍。這一創(chuàng)新使得AI系統(tǒng)在多輪交互場(chǎng)景下的響應(yīng)速度與穩(wěn)定性得到質(zhì)的提升,為智能體AI的商業(yè)化落地掃清了關(guān)鍵障礙。
Vera Rubin平臺(tái)的發(fā)布,標(biāo)志著英偉達(dá)正式進(jìn)軍傳統(tǒng)CPU直銷(xiāo)市場(chǎng),直接挑戰(zhàn)英特爾、AMD等老牌廠(chǎng)商,同時(shí)向全球云計(jì)算巨頭自研的Arm架構(gòu)處理器發(fā)起競(jìng)爭(zhēng)。黃仁勛表示,這一戰(zhàn)略轉(zhuǎn)型將重塑AI硬件市場(chǎng)的競(jìng)爭(zhēng)格局,為智能體AI的規(guī)模化應(yīng)用提供更強(qiáng)大的基礎(chǔ)設(shè)施支持。