谷歌研究院近日宣布推出一項突破性AI技術——名為TurboQuant的免訓練內存壓縮算法,該技術通過創新架構顯著降低大語言模型推理階段的顯存占用,同時保持模型精度不受影響。據官方披露,這項算法可將鍵值緩存(KV Cache)的內存需求壓縮至原有水平的六分之一以下,在特定測試場景中甚至實現八倍性能提升,為AI模型在資源受限環境中的部署開辟了新路徑。
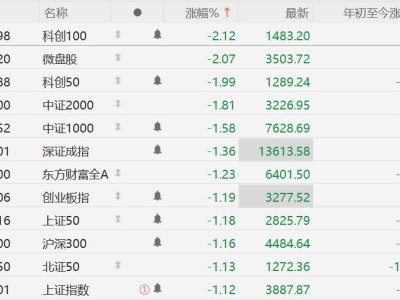
資本市場對這項技術進展迅速作出反應。存儲芯片板塊在消息公布后出現集體回調,其中閃迪股價單日跌幅達6.5%,美光科技與希捷科技分別下跌4%和5%以上。市場分析指出,投資者擔憂TurboQuant若實現規模化應用,可能改變當前高帶寬內存(HBM)的供需格局,尤其是對用于AI訓練的高端存儲芯片需求產生長期影響。
技術核心在于突破傳統量化方法的內存瓶頸。常規向量量化技術為維持精度,需為每個數據塊存儲全精度量化常數,導致額外內存開銷。TurboQuant采用兩階段處理架構:首先通過PolarQuant技術將數據向量從笛卡爾坐標系轉換為極坐標系,分離出代表強度的半徑和代表方向的角度,從幾何結構層面消除冗余存儲;隨后運用量化約翰遜-林登施特勞斯(QJL)算法,以單比特位寬對微小誤差進行數學校正,確保注意力分數計算精度不受損失。
實測數據顯示,該算法可將KV緩存壓縮至3.5比特甚至3比特水平。在"大海撈針"等長文本基準測試中,模型檢索召回率保持100%,且無需針對特定任務進行預處理或微調。這種"數據無感知"特性使其能快速集成到現有AI系統中,顯著降低部署門檻。研究團隊特別強調,壓縮后的模型在處理超長上下文時,顯存占用不再隨文本長度線性增長,為實時交互類應用提供技術支撐。
但技術落地仍面臨現實約束。當前AI推理產業已廣泛采用16位、8位乃至4位量化技術,谷歌宣稱的八倍性能提升是基于與未壓縮的32位模型對比得出,實際生產環境中的效率增益可能低于理論值。更關鍵的是,TurboQuant僅針對推理階段的KV緩存優化,不涉及模型權重本身的壓縮。這意味著部署千億參數模型時,仍需足夠容量的底層硬件支持,算法優化無法突破物理顯存限制。
行業專家指出,這項技術將重塑AI應用的經濟模型。內存開銷的降低使邊緣設備或消費級顯卡能夠運行此前僅限云端處理的長文本任務,軟件優化與硬件依賴的平衡關系發生微妙變化。但這種效率提升可能引發"杰文斯悖論"——當單位計算成本下降時,整體需求反而會因應用場景擴展而上升。長文本推理門檻的降低,或將推動AI多模態應用在企業服務和消費領域的普及,最終對全球算力基礎設施提出更高要求。