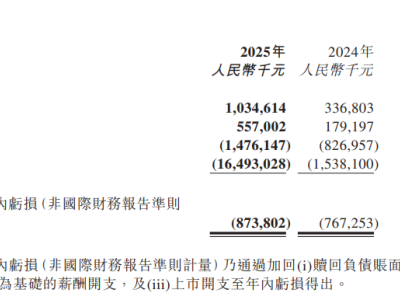
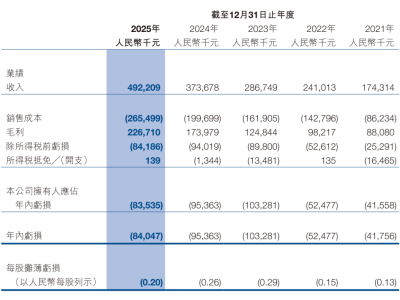
當人工智能僅需幾行文字指令,就能在數秒內生成一段畫面流暢、光影逼真的高清視頻時,傳統視頻創作的邊界正在被徹底打破。OpenAI最新推出的Sora模型,不僅重新定義了視頻生成的可能性,更通過技術革新展現了AI對物理世界規則的深度理解。這一突破標志著AI從信息處理工具向“現實模擬引擎”的跨越,為多領域應用開辟了全新路徑。
傳統視頻生成模型常將動態畫面拆解為獨立幀進行逐幀預測,這種模式在處理長視頻時極易導致畫面閃爍、物體形變或邏輯斷裂。Sora則通過“時空補丁”(Spacetime Patches)技術顛覆了這一邏輯——它將視頻數據轉化為包含時空信息的三維模塊,使時間維度成為數據結構的內在屬性。這種創新讓模型無需復雜建模即可維持長視頻的動態連貫性,如同將電影從散落的膠片重組為自帶劇情關聯的立體拼圖,從根本上解決了穩定性難題。
支撐這一突破的是擴散Transformer(DiT)架構的融合應用。擴散模型以生成質量著稱,而Transformer架構則擅長處理長程依賴關系。Sora將二者結合,利用自注意力機制捕捉時空補丁間的復雜關聯。實驗顯示,模型能精準記憶角色離開畫面數十秒后的服飾細節,甚至讓光影變化遵循真實物理規律。其原生多分辨率訓練策略更突破了傳統模型對畫面比例的限制,可直接生成不同寬高比的視頻,顯著提升了構圖實用性。
Sora的核心價值不僅在于技術架構,更在于其對物理世界的模擬能力。通過海量視頻數據訓練,模型逐漸形成了對基礎物理規律的認知,這種能力被稱為“世界模型”的雛形。在生成場景中,水面會因物體運動產生真實漣漪,角色復雜動作中衣物保持自然垂墜,甚至能模擬流體動力學與剛體碰撞的微妙效果。例如,當生成“槳板后空翻”場景時,模型能精準呈現水的浮力反饋、人體重心轉移及水花形態,展現出超越像素拼接的內在邏輯一致性。
隨著技術迭代,Sora的功能邊界持續擴展。新一代模型不僅提升了視頻真實感與指令可控性,更實現了從片段生成到故事敘事的跨越——能處理跨鏡頭的復雜指令。其原生集成的音頻生成能力尤為突出,可根據畫面內容同步生成環境音、動作音效甚至角色對話,并確保口型與發音精準匹配。這一突破標志著AI視頻生成正式邁入視聽融合的多模態時代。
Sora的誕生意義遠超工具創新范疇。它證明當AI模型規模達到臨界點時,通過海量數據學習可涌現出對現實世界復雜規律的模擬能力。這種能力為通用人工智能(AGI)發展提供了新思路,也為科學模擬、自動駕駛、機器人控制等領域的應用帶來無限可能。它不再局限于生成視頻,而是在嘗試構建一個可計算、可理解的數字世界。