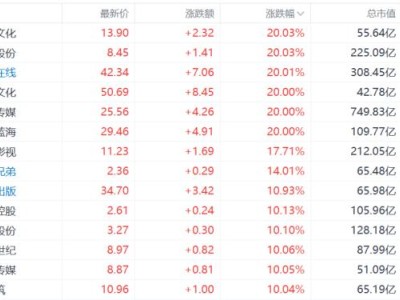
2 月 10 日消息,科技媒體 9to5Mac 昨日(2 月 9 日)發布博文,報道稱蘋果公司攜手中國人民大學(簡稱人大),推出 VSSFlow 新型 AI 模型,突破了傳統音頻生成技術的瓶頸,僅需單一系統即可從無聲視頻中同時生成逼真的環境音效與人類語音。
該模型的核心能力在于“化靜為動”,能夠直接處理無聲視頻數據,在單一系統的框架下,同步生成與畫面高度匹配的環境音效以及精準的語音對話。該成果不僅解決了過去音頻生成模型功能單一的問題,更在生成質量上達到了行業領先水平。
援引博文介紹,在 VSSFlow 問世之前,行業內的模型往往存在嚴重的偏科現象:視頻轉聲音模型(V2S)難以生成清晰的語音,而文本轉語音模型(TTS)又無法處理復雜的環境噪音。
傳統的解決方案通常是將兩者分階段訓練,這不僅增加了系統的復雜性,還常因任務沖突導致性能下降。VSSFlow 則另辟蹊徑,采用了 10 層架構設計并引入“流匹配”技術,讓模型自主學習如何從隨機噪聲中,重構出目標聲音信號。
研究團隊在訓練過程中發現了一個令人驚喜的現象:聯合訓練不僅沒有導致任務干擾,反而產生了“互助效應”。即語音數據的訓練提升了音效生成的質量,而音效數據的加入也優化了語音的表現。
團隊為了實現這一效果,向模型投喂了混合數據,包括配有環境音的視頻、配有字幕的說話視頻以及純文本轉語音數據,并利用合成樣本微調模型,讓其學會同時輸出背景音與人聲。
在實際運行中,VSSFlow 以每秒 10 幀的頻率從視頻中提取視覺線索來塑造環境音效,同時依據文本腳本精確引導語音生成。