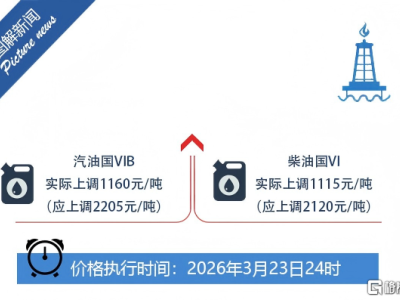
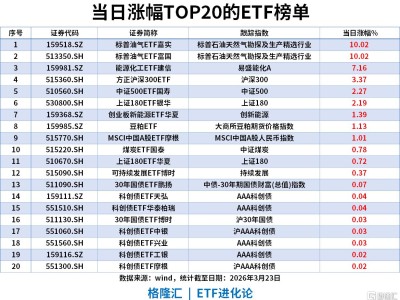
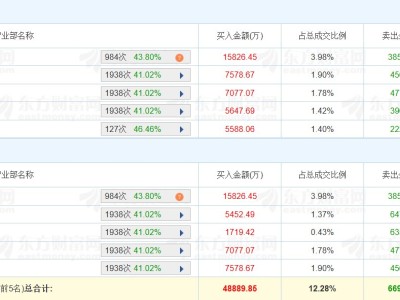
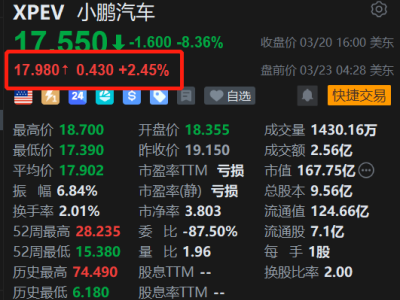
沒有博士學位,沒有發表過學術論文,卻憑借開源項目和改進研究成功入職OpenAI——Keller Jordan的經歷正在AI圈引發熱議。這位2020年畢業于加州大學圣地迭戈分校的年輕人,用行動證明:在頂尖AI實驗室,行動力和開源貢獻可能比論文數量更具說服力。
在"NanoGPT speedrun"挑戰中,Keller將訓練Transformer模型的token效率提升3.8倍,訓練成本從100億token驟降至27億。更令人驚嘆的是,他通過代碼極簡化(僅537行)、環境快速部署(8×H100集群20分鐘完成安裝)和超低嘗試成本(單次8美元),徹底打破了AI研究的高算力壁壘。"這讓全球研究者都能用消費級顯卡驗證新想法。"某獨立開發者如此評價。
2024年末,Keller推出的Muon優化器再次震動學術界。這種針對神經網絡隱藏層的優化算法,通過正交化處理SGD動量更新矩陣,在CIFAR-10和NanoGPT訓練中刷新世界紀錄。實驗數據顯示,在bf16精度下,Muon比主流的AdamW優化器計算開銷降低40%,而模型收斂速度提升顯著。盡管尚未發表學術論文,但其完全開源的代碼庫已獲得超3000次星標。
OpenAI的橄欖枝在2024年12月到來。有趣的是,面對Muon引發的關注,Keller拒絕撰寫傳統論文:"大多數優化器研究都是虛假繁榮,我更愿意用持續改進的代碼說話。"這種務實態度與OpenAI的文化不謀而合。入職后,他繼續在GitHub更新Muon的改進版本,最新代碼顯示已支持動態精度調整。
Keller的故事并非孤例。谷歌DeepMind的Sholto Douglas憑借在Jax開源社區的深度貢獻,成為Gemini項目的核心成員;半退休量化分析師Andy Jones通過自研GPU加速環境,展示出超越論文的工程能力,最終被Anthropic錄用。這些案例揭示著頂尖AI實驗室人才觀的轉變:可驗證的貢獻、開源社區影響力,正在取代論文數量成為新的敲門磚。