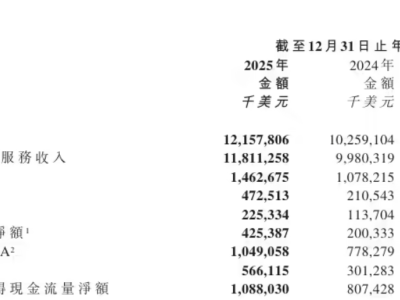
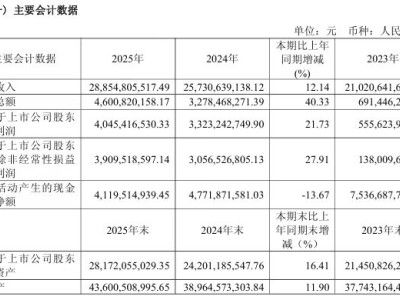
中文大模型領域的競爭已悄然進入貼身肉搏的白熱化階段。隨著中文大模型基準測評SuperCLUE正式發布2026年3月最新一期成績單,22款國內外頂尖AI模型在這場“期末大考”中交出了答卷。結果顯示,海外巨頭雖然依舊把持著總分榜單的頭部位置,但國產大模型已經不再是跟隨者,而是憑借極為兇猛的態勢,在多個維度完成了史詩級的逼近與反超。
在本次橫跨數學推理、科學推理、代碼生成等六大核心高難度任務的全面檢驗中,Anthropic的Claude-Opus-4.6(max)、Google的Gemini-3.1-Pro-Preview(high)與OpenAI的GPT-5.4(xhigh)依然穩居總分前三甲,構筑了極強的技術壁壘。然而,真正讓業界震動的是緊隨其后的中國身影。
字節跳動旗下的豆包大模型以71.53分的高分強勢霸榜國內第一,直接躋身全球第一梯隊。更為致命的是,其總分與位列第三的GPT-5.4僅有微乎其微的0.95分差距,這意味著在綜合能力上,國產頭部模型已經實現了與全球最頂尖水平的實質性“并跑”。特別是在極其考驗模型邏輯與執行力的智能體任務規劃維度,豆包更是直接撕開防線,反超了部分海外頂尖模型,強勢躋身全球前五。
除了字節的突圍,本次測評還見證了另一支國產生力軍的崛起。小米集團在AI底層技術上的重金投入開始顯現成效,其MiMo-V2系列兩款模型雙雙殺入榜單。其中定位旗艦的MiMo-V2-Pro以60.67分穩居閉源模型前列,尤其在門檻極高的數學推理任務中,硬核拿下了84.03分的驚艷單科成績,展現了極強的底層推理功底。而其輕量級開源版本MiMo-V2-Flash雖然總分略顯遜色,但在代碼生成等垂直細分場景中依然暴露出不俗的潛力。如果說閉源賽道的中外對決令人血脈僨張,那么開源賽道則完全淪為了國產大模型的“主場表演”。
本次測評數據顯示,國產開源模型不僅整體表現亮眼,更是呈現出斷層式領先的碾壓態勢。在開源榜單中,Kimi-K2.5-Thinking、Qwen3.5-397B-A17B-Thinking等國產選手毫無懸念地包攬了前三名,將海外同類開源模型遠遠甩在身后。
從字節豆包的貼身緊逼,到小米MiMo的單科爆發,再到國產開源陣營的集體霸榜,SuperCLUE的這份3月榜單不僅是一份成績單,更是一份宣言書——在全球大模型的終極角逐中,“中國力量”已經具備了全方位撼動舊秩序的硬實力。