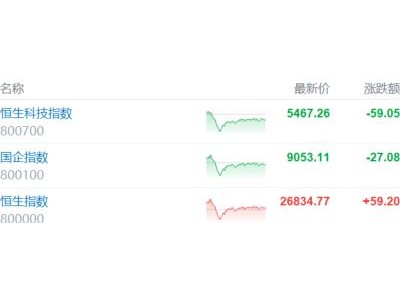
在人工智能產品開發領域,一場靜悄悄的革命正在發生。硅谷的頂尖團隊正逐步淘汰傳統的產品需求文檔(PRD),轉而采用一種名為evals的新型動態評測框架。這一轉變標志著AI產品開發從靜態規劃向動態優化的重大跨越。
傳統PRD的局限性在AI時代愈發凸顯。以ChatGPT為代表的生成式AI產品,其輸出結果具有顯著的不確定性。用戶輸入的細微變化、上下文語境的差異,甚至模型參數的調整,都可能導致完全不同的響應。這種動態特性使得PRD中"用戶點擊按鈕后顯示彈窗"這類確定性描述變得毫無意義。某頭部AI公司工程師坦言:"我們曾經為某個功能編寫了50頁PRD,但模型迭代兩次后,其中80%的內容就已經過時了。"
evals框架的核心在于構建持續驗證機制。OpenAI等領先企業通過自動化測試套件、黃金對話集和AI評審系統,將產品規范轉化為可執行的評測指標。這種方法徹底改變了產品經理的工作模式——從撰寫功能清單轉向設計實驗場景。某轉型團隊負責人描述:"現在我們的工作流是:設計測試用例→收集模型輸出→分析失敗模式→優化產品定義,形成一個持續改進的閉環。"
黃金對話集作為evals的基礎組件,實質上是AI產品的"理想交互劇本"。Yelp團隊在重構招聘助手時,詳細定義了200多個典型場景的對話流程,包括如何引導用戶完善簡歷信息、如何處理模糊的職業目標等。這種設計方式使產品團隊能夠精準控制模型的交互風格和邊界條件,較傳統PRD提升了60%的需求覆蓋率。
錯誤分析系統則是evals的質量控制中樞。某大型語言模型團隊每天處理超過10萬條用戶交互日志,通過自然語言處理技術自動識別輸出偏差。他們建立的失敗模式庫已包含37類典型問題,從事實性錯誤到倫理偏差應有盡有。這些數據不僅用于即時修復,更被轉化為訓練評測模型的標注數據,形成"問題發現-模型優化-效果驗證"的自動化鏈條。
AI評審系統的引入解決了人工評估的效率瓶頸。Anthropic開發的倫理評估模型,能夠在秒級時間內判斷對話是否符合安全準則,準確率達到人類專家的92%。這種機制迫使團隊將質量標準顯性化——某團隊為定義"有害內容"就召開了20余次跨部門研討會,最終形成包含127個子類別的評判標準。
這場變革正在重塑產品開發的全鏈條。RAG系統需要分別評估檢索準確率和生成忠實度,Agent架構則要追蹤工具調用鏈中的每個決策節點。某自動駕駛團隊將決策系統拆解為43個評測維度后,系統故障率在三個月內下降了78%。產品經理的角色也隨之進化,某招聘平臺的產品負責人表示:"現在我們需要同時掌握對話設計、數據分析和模型評估技能,這簡直是產品經理的'全棧化'。"
隨著多模態AI和具身智能的興起,evals框架的價值愈發凸顯。某機器人公司采用動態評測系統后,將硬件-軟件協同開發周期從18個月縮短至9個月。工程師們通過實時評測數據調整機械臂的運動參數,同時優化語音交互的響應策略,這種并行開發模式在傳統PRD體系下難以實現。
這場靜悄悄的革命正在重新定義AI產品的開發規則。當模型迭代速度以周計算時,靜態文檔注定成為歷史。那些率先建立動態評測體系的團隊,正在這場競賽中建立起難以逾越的技術壁壘。正如某風險投資人觀察到的:"現在評估AI初創公司,我們首先看他們有沒有成熟的evals系統,這比產品原型更能說明技術實力。"