文檔識別領域迎來重要進展,DeepSeek團隊正式推出新一代文檔識別模型DeepSeek-OCR 2。該模型在繼承前代架構優勢的基礎上,通過創新性的視覺編碼器設計,實現了對復雜文檔結構更精準的解析能力。
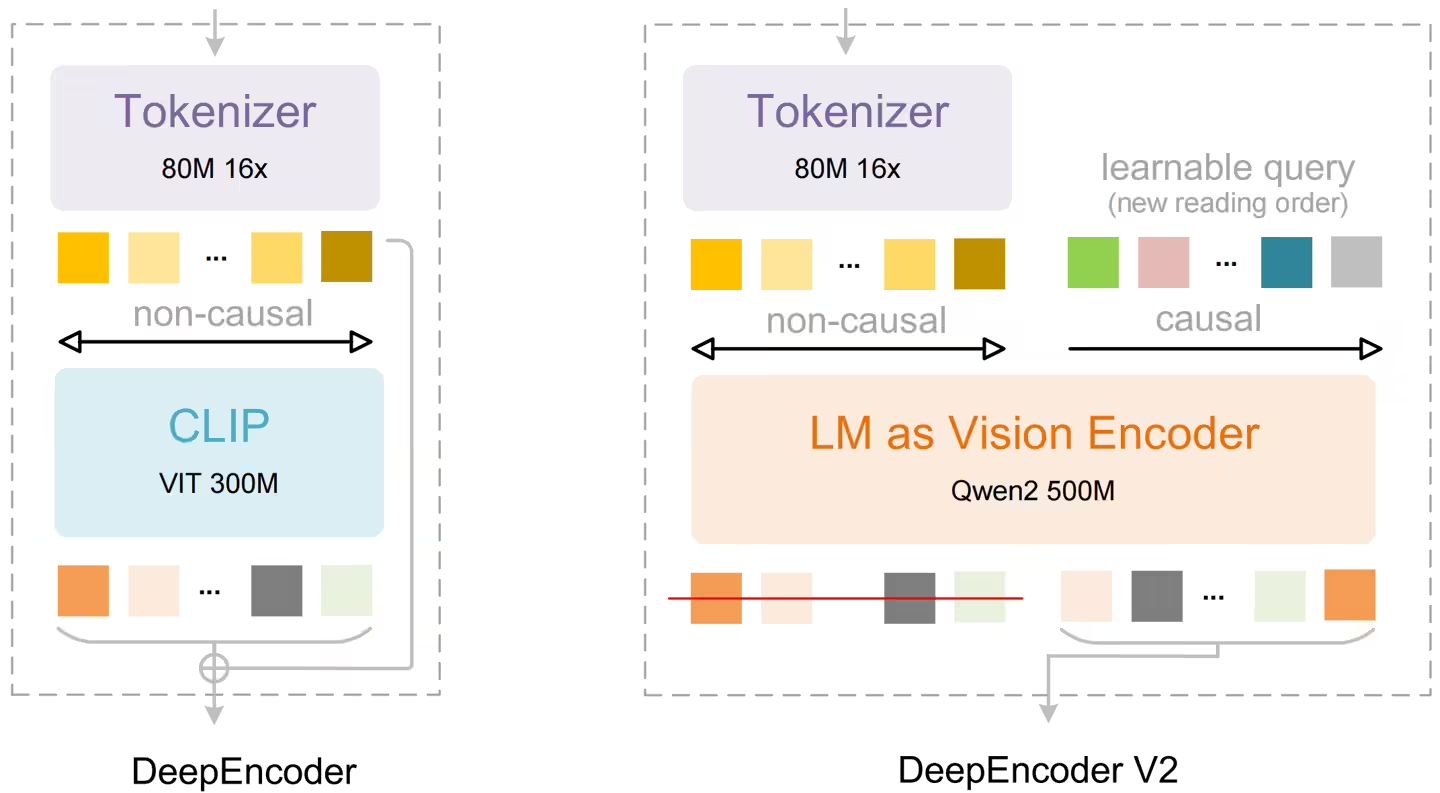
傳統視覺語言模型在處理文檔圖像時,通常采用固定柵格順序切割視覺元素,這種處理方式雖便于實現,卻與人類閱讀時的語義跳躍特性存在顯著差異。特別是在學術論文、財務報表等版式復雜的場景中,視覺元素間的邏輯關聯往往超越空間位置關系,單純依賴空間順序的解析方式容易產生理解偏差。
研究團隊提出的DeepEncoder V2架構突破了這一局限。該架構通過引入"視覺因果流"機制,使編碼器能夠動態調整視覺token的處理順序。具體實現上,系統同時運行雙向注意力與因果注意力兩種模式:前者負責全局視覺信息感知,后者通過可學習的因果查詢token逐步構建語義順序。這種雙重注意力機制確保模型在編碼階段就能完成視覺元素的智能排序。
在架構設計方面,新模型延續了編解碼框架但進行了關鍵優化。編碼器先將圖像壓縮為256-1120個視覺token,經DeepEncoder V2重組語義順序后,交由基于混合專家架構(MoE)的語言模型解碼。這種設計在保持計算效率的同時,將解碼負擔控制在合理范圍內,資源消耗與前代模型基本持平。
性能驗證在OmniDocBench v1.5基準測試中進行,該測試集包含中英文學術論文、商業報告等12類文檔。實驗數據顯示,在視覺token數量減少的情況下,新模型整體識別準確率達91.09%,較前代提升3.73個百分點。特別在閱讀順序指標上,編輯距離從0.085優化至0.057,證明其對文檔結構的理解能力顯著增強。
實際應用表現同樣亮眼。生產環境測試顯示,在線用戶日志圖像的重復識別率下降33%(從6.25%降至4.17%),PDF批處理數據的重復率降低22%(從3.69%降至2.88%)。這些改進表明模型在保持高壓縮率的同時,有效提升了復雜場景下的處理穩定性。