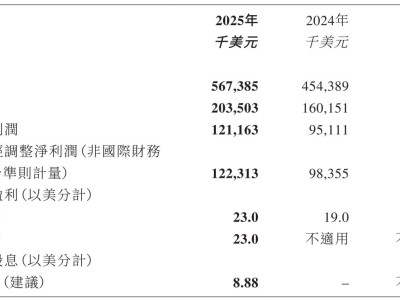
GLM-5是怎么煉成的?
現(xiàn)在,它背后的論文終于完全公開了。
論文的名字也很直接:告別Vibe Coding,邁入智能體工程(Agentic Engineering)。
也正如我們之前實(shí)測(cè)的那般,它可以自己連續(xù)跑代碼超過24小時(shí)、700次工具調(diào)用、800次上下文切換,從零直接手搓一個(gè)Game Boy Advance(GBA)模擬器。
一言蔽之,GLM-5把開源AI拽進(jìn)了長(zhǎng)任務(wù)時(shí)代。
外國(guó)網(wǎng)友直呼“GLM-5是最好的開源模型”:
并且還認(rèn)為“極大拉小了和Claude Opus 4.6之間的距離”:
除此之外,資本市場(chǎng)的表現(xiàn)也是可以從側(cè)面印證一家大模型公司的實(shí)力。
畢竟春節(jié)期間,智譜股價(jià)飆升的程度,毋庸置疑,大家有目共睹。
現(xiàn)如今,這份長(zhǎng)達(dá)40頁(yè)的論文,徹底揭開了它背后的一切技術(shù)秘密。亮點(diǎn)如下:
架構(gòu)方面:
在上一代經(jīng)過驗(yàn)證的ARC(智能體、推理與編程)能力和MoE之上,引入DeepSeek同款稀疏注意力(DSA);成本大幅打下來了的同時(shí),長(zhǎng)上下文能力卻一點(diǎn)沒丟。
后訓(xùn)練方面:
全新構(gòu)建的異步強(qiáng)化學(xué)習(xí)基礎(chǔ)設(shè)施,把生成和訓(xùn)練解耦,加上獨(dú)創(chuàng)的異步智能體RL算法,讓效率大幅提升。
芯片適配方面:
GLM-5完成了與華為昇騰、摩爾線程、海光、寒武紀(jì)、昆侖芯、沐曦以及燧原等國(guó)產(chǎn)芯片的全棧適配。
這也讓不少網(wǎng)友在看完論文之后直呼:
在成本效率方面,美國(guó)的AI趕不上中國(guó)。
接下來,就讓我們一起深入扒一扒這篇讓外國(guó)網(wǎng)友羨慕的技術(shù)論文。
GLM-5的三大關(guān)鍵技術(shù)
在深入技術(shù)之前,我們需要先理解GLM-5在技術(shù)發(fā)展當(dāng)下所面臨的難題,即大模型需要真正開始干復(fù)雜的難活兒了。
因?yàn)樵贕LM-4.5時(shí)代,智譜已經(jīng)證明了將ARC能力融合進(jìn)單一MoE架構(gòu)是完全可行的。
但當(dāng)模型真正投入到復(fù)雜的軟件工程、長(zhǎng)周期多輪對(duì)話的真實(shí)業(yè)務(wù)中時(shí),算力成本和真實(shí)環(huán)境適應(yīng)性成為了老大難的問題。
△GLM-5 的整體訓(xùn)練流程
GLM-5要解決的就是這些瓶頸。因此,它在核心技術(shù)方面祭出了三把板斧。
第一板斧:引入DeepSeek同款稀疏注意力機(jī)制
在Transformer架構(gòu)中,傳統(tǒng)的密集注意力計(jì)算復(fù)雜度是隨著上下文長(zhǎng)度呈平方級(jí)(O(N2))增長(zhǎng)的。
當(dāng)上下文窗口擴(kuò)展至200K甚至更長(zhǎng)時(shí),計(jì)算成本將變得極其昂貴,這成為限制智能體處理復(fù)雜任務(wù)的主要瓶頸。
GLM-5的解法是引入DSA這個(gè)動(dòng)態(tài)稀疏注意力機(jī)制,它的核心理念是用動(dòng)態(tài)的細(xì)粒度選擇機(jī)制替換傳統(tǒng)的密集注意力。與固定的滑動(dòng)窗口模式不同,DSA 會(huì)“審視”內(nèi)容,動(dòng)態(tài)決定哪些Token是重要的。
然而,直接訓(xùn)練一個(gè)基于DSA的超大模型無異于走鋼絲,很容易因?yàn)橄∈杌瘞淼男畔G失而導(dǎo)致梯度爆炸或模型崩塌。
因此,GLM-5團(tuán)隊(duì)采取了一種極其巧妙的繼續(xù)預(yù)訓(xùn)練策略,主要包含兩個(gè)步驟:
稠密預(yù)熱(Dense Warm-up):模型并非一上來就搞稀疏。在預(yù)訓(xùn)練的初始階段,模型依然使用相對(duì)稠密的注意力機(jī)制(類似于MLA的變體),讓模型先看全所有的信息,建立起全局的、穩(wěn)固的語(yǔ)義表征能力。這就好比一個(gè)人在學(xué)習(xí)速讀之前,必須先扎扎實(shí)實(shí)地精讀。
平滑過渡與稀疏訓(xùn)練(Sparse Training):當(dāng)模型具備了良好的基礎(chǔ)后,開始逐步提高稀疏度。DSA的核心邏輯是:在計(jì)算當(dāng)前Token的注意力時(shí),不再關(guān)注歷史上的所有Token,而是通過一個(gè)動(dòng)態(tài)的路由機(jī)制(Routing Mechanism),只挑選出與之最相關(guān)的Top-K個(gè)Token進(jìn)行計(jì)算。
△MLA與DSA訓(xùn)練的SFT損失曲線對(duì)比
根據(jù)技術(shù)報(bào)告披露的數(shù)據(jù),這一板斧砍下去,效果是立竿見影的:
KV Cache開銷驟降75%:這意味著同樣的顯卡,現(xiàn)在可以支撐4倍以上的并發(fā)請(qǐng)求,或者處理長(zhǎng)達(dá)4倍的上下文。推理速度提升3倍:注意力計(jì)算的FLOPS被大幅削減,首字響應(yīng)時(shí)間(TTFT)和每秒生成Token數(shù)(TPS)都達(dá)到了行業(yè)頂尖水平。長(zhǎng)文本能力幾乎無損:這是最令人不可思議的一點(diǎn)。在著名的大海撈針以及諸如RULER等長(zhǎng)文本復(fù)雜推理評(píng)測(cè)中,引入DSA的GLM-5與全稠密模型相比,性能下降微乎其微(小于0.5%)。第二板斧:異步多任務(wù)強(qiáng)化學(xué)習(xí)
如果說DSA解決的是推理成本問題,那么GLM-5的第二板斧,解決的就是訓(xùn)練效率問題,尤其是決定模型最終智商的后訓(xùn)練階段。
當(dāng)前業(yè)界主流的強(qiáng)化學(xué)習(xí)對(duì)齊算法依然是PPO(近端策略優(yōu)化)。
標(biāo)準(zhǔn)的PPO是一個(gè)高度同步的過程,涉及到四個(gè)模型,即Actor生成模型、Reference參考模型、Critic評(píng)論家模型、Reward獎(jiǎng)勵(lì)模型在多臺(tái)GPU上的協(xié)同。
這種“走一步,停一下”的同步機(jī)制,導(dǎo)致整個(gè)集群的GPU利用率經(jīng)常徘徊在20%-30%左右,大部分算力都浪費(fèi)在等待網(wǎng)絡(luò)通信和進(jìn)程同步上了。
為了打破這個(gè)瓶頸,智譜基于4.5時(shí)代的Slime框架,為GLM-5從底層重寫了一套異步強(qiáng)化學(xué)習(xí)基礎(chǔ)設(shè)施(Asynchronous RL Infrastructure)。
它的核心設(shè)計(jì)是將訓(xùn)練引擎和推理引擎解耦到不同的GPU設(shè)備上。推理引擎持續(xù)生成軌跡,一旦生成數(shù)量達(dá)到預(yù)定閾值,這批數(shù)據(jù)就被發(fā)送到訓(xùn)練引擎更新模型。為減少策略滯后并保持訓(xùn)練的近似同策略性,推理引擎的模型權(quán)重會(huì)定期與訓(xùn)練側(cè)同步。
這種完全異步的訓(xùn)練范式,通過減少Agent rollout期間的“氣泡”時(shí)間,顯著提升了GPU利用率和訓(xùn)練效率。
但要支撐這種異步架構(gòu),還有幾個(gè)關(guān)鍵技術(shù)難題需要解決:
第一,Token-in-Token-out(TITO)代替Text-in-Text-out。
在RL rollout設(shè)置中,TITO意味著訓(xùn)練流程直接消費(fèi)推理引擎生成的精確tokenization和解碼token流來構(gòu)建學(xué)習(xí)軌跡。相比之下,Text-in-Text-out將rollout引擎視為返回最終文本的黑箱,訓(xùn)練器需要重新tokenization重建軌跡。
這個(gè)看似微小的選擇實(shí)際上影響巨大:重新tokenization可能在token邊界、空白處理、截?cái)嗷蛱厥鈚oken放置上引入細(xì)微不匹配,從而影響對(duì)單個(gè)token采樣概率的估計(jì)。GLM-5實(shí)現(xiàn)了一個(gè)TITO網(wǎng)關(guān),攔截rollout任務(wù)的所有生成請(qǐng)求并記錄每個(gè)軌跡的tokenID和元數(shù)據(jù),將繁瑣的tokenID處理從下游Agent rollout邏輯中隔離出來。
第二,直接雙側(cè)重要性采樣解決離策略偏差。
在異步設(shè)置中,rollout引擎可能在單個(gè)軌跡生成過程中經(jīng)歷多次更新,這使得追蹤歷史訓(xùn)練側(cè)模型的精確行為概率在計(jì)算上不可行——維護(hù)多個(gè)歷史模型權(quán)重顯然不現(xiàn)實(shí)。
研究團(tuán)隊(duì)采用簡(jiǎn)化方案:將rollout期間生成的對(duì)數(shù)概率作為直接行為代理,通過計(jì)算重要性采樣比rt(θ) = πθ/πrollout,丟棄傳統(tǒng)的πθ_old,消除單獨(dú)舊策略推理的計(jì)算開銷。同時(shí)采用雙側(cè)校準(zhǔn)token級(jí)掩碼策略,將信任域限制在[1-ε_(tái)l, 1+ε_(tái)h],對(duì)落在此區(qū)間之外的token完全屏蔽梯度計(jì)算。
第三,DP感知路由加速長(zhǎng)上下文推理。
在多輪Agent工作負(fù)載中,來自相同rollout的順序請(qǐng)求共享相同前綴。研究團(tuán)隊(duì)提出通過一致性哈希將每個(gè)rollout ID映射到固定數(shù)據(jù)并行(DP)rank,并結(jié)合哈希空間上的輕量級(jí)動(dòng)態(tài)負(fù)載重新平衡。這避免了冗余的預(yù)填充計(jì)算,無需跨DP rank的KV同步,隨著rollout長(zhǎng)度增加,預(yù)填充成本仍與增量token成正比。
第三板斧:投喂真實(shí)世界數(shù)據(jù)
傳統(tǒng)SFT數(shù)據(jù)往往依賴標(biāo)準(zhǔn)答案,但真實(shí)世界是復(fù)雜多變的。
為了讓模型具備真正的工程能力,GLM-5的第三板斧,就是構(gòu)建大量可驗(yàn)證的真實(shí)世界環(huán)境數(shù)據(jù)。
整個(gè)SFT語(yǔ)料庫(kù)涵蓋三大類別:通用對(duì)話、推理、編程與Agent。
值得注意的是,GLM-5在SFT階段將最大上下文長(zhǎng)度擴(kuò)展至202752個(gè)token,并支持三種不同的思考特征:
交錯(cuò)思考:模型在每次響應(yīng)和工具調(diào)用前進(jìn)行思考,提升指令遵循和生成質(zhì)量;保留思考:在Coding Agent場(chǎng)景中,模型自動(dòng)在多輪對(duì)話中保留所有思考?jí)K,復(fù)用已有推理而非重新推導(dǎo),減少信息丟失和不一致性;輪級(jí)思考:支持在會(huì)話中對(duì)每輪推理進(jìn)行精細(xì)控制,輕量級(jí)請(qǐng)求可禁用思考降低延遲,復(fù)雜任務(wù)可啟用思考提升精度和穩(wěn)定性。
為了支持Agent RL,研究團(tuán)隊(duì)還構(gòu)建了大規(guī)模的、可驗(yàn)證的可執(zhí)行環(huán)境:
軟件工程環(huán)境:基于真實(shí)世界的Issue-PR對(duì),采用RepoLaunch框架自動(dòng)分析倉(cāng)庫(kù)安裝和依賴設(shè)置,構(gòu)建可執(zhí)行環(huán)境并生成測(cè)試命令。最終跨數(shù)千個(gè)倉(cāng)庫(kù)、涵蓋9種編程語(yǔ)言(Python、Java、Go、C、C++、Javascript、Typescript、PHP、Ruby),構(gòu)建了超過10000個(gè)可驗(yàn)證環(huán)境。
終端環(huán)境:采用三階段Agent數(shù)據(jù)合成流程——任務(wù)草稿生成、具體任務(wù)實(shí)現(xiàn)、迭代任務(wù)優(yōu)化。從種子任務(wù)出發(fā),利用LLM生成可驗(yàn)證的終端任務(wù)草稿,由構(gòu)建Agent在Harbor格式中實(shí)例化為具體任務(wù)(結(jié)構(gòu)化任務(wù)描述、Docker化執(zhí)行環(huán)境、測(cè)試腳本),再由精煉Agent迭代優(yōu)化。整體流程產(chǎn)出數(shù)千個(gè)多樣化終端環(huán)境,Docker構(gòu)建精度超過90%。
搜索任務(wù):構(gòu)建Web知識(shí)圖譜,以低至中頻實(shí)體為種子節(jié)點(diǎn)擴(kuò)展多跳鄰域,將每個(gè)子圖轉(zhuǎn)化為隱式編碼多實(shí)體關(guān)系鏈的問題。再經(jīng)過三階段過濾(刪除無工具推理模型能答對(duì)的、過濾早期Agent能幾步解決的、雙向驗(yàn)證拒絕非唯一答案或不一致證據(jù)的),最終獲得高質(zhì)量、高難度的多跳問答對(duì)。
PPT生成:采用多層級(jí)獎(jiǎng)勵(lì)機(jī)制——第1級(jí)關(guān)注靜態(tài)標(biāo)記屬性(定位、間距、顏色、字體等),第2級(jí)評(píng)估運(yùn)行時(shí)渲染屬性(元素寬高、邊界框等),第3級(jí)引入視覺感知特征(異常空白模式等)。最終生成的頁(yè)面中嚴(yán)格符合16:9寬高比的比例從40%提升至92%,頁(yè)面溢出顯著減少。
大模型的測(cè)試也更難了
技術(shù)的進(jìn)步最終需要經(jīng)受評(píng)測(cè)的檢驗(yàn)。
GLM-5的論文不僅展示了其在傳統(tǒng)榜單上的成績(jī),更揭示了一個(gè)趨勢(shì):大模型的測(cè)試正在變得更難、更貼近真實(shí)。
在Humanity’s Last Exam(HLE)、SWE-bench Verified、BrowseComp等關(guān)鍵榜單上,數(shù)據(jù)顯示,GLM-5在SWE-bench Verified上得分77.8%,在開源模型中達(dá)到SOTA,優(yōu)于Gemini 3 Pro,并與Claude Opus 4.5相當(dāng)。
在HLE(含工具)測(cè)試中,GLM-5得分50.4,優(yōu)于Claude Opus 4.5和Gemini 3 Pro。
在Artificial Analysis Intelligence Index v4.0中,GLM-5得到50分,成為新的開源SOTA模型,這是開放權(quán)重模型首次在該指數(shù)中達(dá)到50分。
然而,智譜團(tuán)隊(duì)認(rèn)為,傳統(tǒng)的SWE-bench已經(jīng)不夠看了。
因?yàn)樗且粋€(gè)靜態(tài)、公開且發(fā)布超過2年的測(cè)試集,模型可能存在記憶效應(yīng)。
為此,GLM-5團(tuán)隊(duì)推出了CC-Bench-V2,一個(gè)完全自動(dòng)化的、模擬真實(shí)軟件開發(fā)的評(píng)測(cè)集,涵蓋前端、后端和長(zhǎng)程任務(wù)。
在前端評(píng)估中,團(tuán)隊(duì)引入了Agent-as-a-Judge技術(shù),通過GUI Agent模擬用戶交互,驗(yàn)證生成項(xiàng)目的功能正確性。
結(jié)果顯示,GLM-5的構(gòu)建成功率(BSR)達(dá)到98.0%,在檢查項(xiàng)成功率(CSR)上與Claude Opus 4.5具備競(jìng)爭(zhēng)力。
在后端評(píng)估中,GLM-5在真實(shí)開源項(xiàng)目上的Pass@1達(dá)到25.8%,與Claude Opus 4.5相當(dāng),顯著領(lǐng)先于GLM-4.7。
更值得一提的是長(zhǎng)程任務(wù)評(píng)估。CC-Bench-V2通過挖掘已合并的Pull Request構(gòu)建多步鏈?zhǔn)饺蝿?wù),評(píng)估模型在增量開發(fā)中的上下文跟蹤與規(guī)劃能力。
雖然GLM-5在此項(xiàng)上較GLM-4.7有顯著提升,但與Claude Opus 4.5仍有差距。團(tuán)隊(duì)坦言,這是因?yàn)殒準(zhǔn)饺蝿?wù)中錯(cuò)誤會(huì)累積放大,縮小這一差距需要在長(zhǎng)上下文一致性和長(zhǎng)程自糾錯(cuò)方面繼續(xù)突破。
這一系列評(píng)測(cè)結(jié)果釋放了兩個(gè)明確信號(hào):
第一,GLM-5 是開源界的第一個(gè)“全站工程師”,讓 AI 能自主執(zhí)行超長(zhǎng)、超復(fù)雜的任務(wù);
第二,通過單體MoE架構(gòu)統(tǒng)一Agent、推理與代碼能力的可行性得到了驗(yàn)證,同時(shí)證明了RL在復(fù)雜代碼生成中的巨大潛力。這對(duì)閉源模型而言,無疑是一種巨大的沖擊。
One More Thing
在論文的最后,團(tuán)隊(duì)透露了一個(gè)有趣的彩蛋——Pony Alpha實(shí)驗(yàn)。
在論文公開前,GLM-5曾以Pony Alpha為代號(hào),匿名發(fā)布在OpenRouter平臺(tái)上。隱去品牌信息后,模型憑借卓越的性能在社區(qū)引發(fā)轟動(dòng)。
初步統(tǒng)計(jì)顯示,25%的用戶推測(cè)它是Claude Sonnet 5,20%認(rèn)為是Grok的新版本,僅有部分用戶猜中了GLM-5。
這次匿名測(cè)試打破了先入為主的地緣偏見,讓社區(qū)的認(rèn)可回歸到了“好用與否”這一最純粹的技術(shù)本質(zhì)。
最終確認(rèn)Pony Alpha真身即是GLM-5,這對(duì)團(tuán)隊(duì)是一次巨大的鼓舞,也有力回?fù)袅碎L(zhǎng)期以來外界對(duì)中國(guó)本土模型技術(shù)水準(zhǔn)的質(zhì)疑。
不僅如此,這次GLM-5論文公布之后,在海外已經(jīng)有不少人當(dāng)教程來學(xué)習(xí)了。