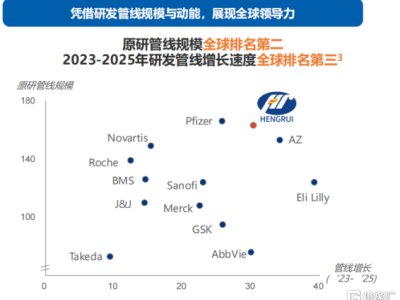
在最新發布的中文大模型基準測評SuperCLUE中,國產大模型展現出強勁競爭力,標志著中國人工智能技術正從技術追趕邁向全球領跑。本次測評覆蓋數學推理、科學計算、代碼生成等六大核心領域,22款國內外主流模型同臺競技,國產模型在多個維度實現突破性進展。
海外閉源模型仍占據技術制高點,但國產模型已形成有力挑戰。Anthropic的Claude-Opus-4.6、Google的Gemini-3.1-Pro和OpenAI的GPT-5.4分列全球前三,但字節跳動旗下豆包(Doubao-Seed-2.0-pro)以71.53分緊隨其后,與GPT-5.4的差距縮小至0.95分。在智能體任務規劃專項中,豆包更超越部分海外模型躋身全球前五,展現出在復雜場景下的規劃能力優勢。
跨界玩家小米集團在數學推理領域表現亮眼。其MiMo-V2-Pro模型以60.67分位列閉源模型前列,在數學專項測試中斬獲84.03分的高分。更值得關注的是,小米同時推出開源版本MiMo-V2-Flash,該模型在代碼生成等場景中展現出快速迭代能力,形成"專業版+輕量版"的雙模布局。
開源賽道成為國產模型的主戰場。Kimi-K2.5-Thinking與Qwen3.5-397B等模型包攬開源榜單前三名,整體表現顯著優于海外同類產品。測評數據顯示,國產開源模型在多任務處理、資源占用等關鍵指標上形成代際優勢,正吸引全球開發者構建生態應用。
技術競賽焦點正從參數規模轉向實戰能力。本次測評顯示,中文大模型已突破語言理解范疇,在邏輯推理、多模態交互等硬核領域形成完整技術棧。隨著豆包等模型在通用能力上的突破,以及小米等企業在垂直領域的深耕,國產大模型正在重構全球AI技術競爭格局。這種轉變不僅體現在分數追趕,更反映在工程化落地能力的顯著提升。