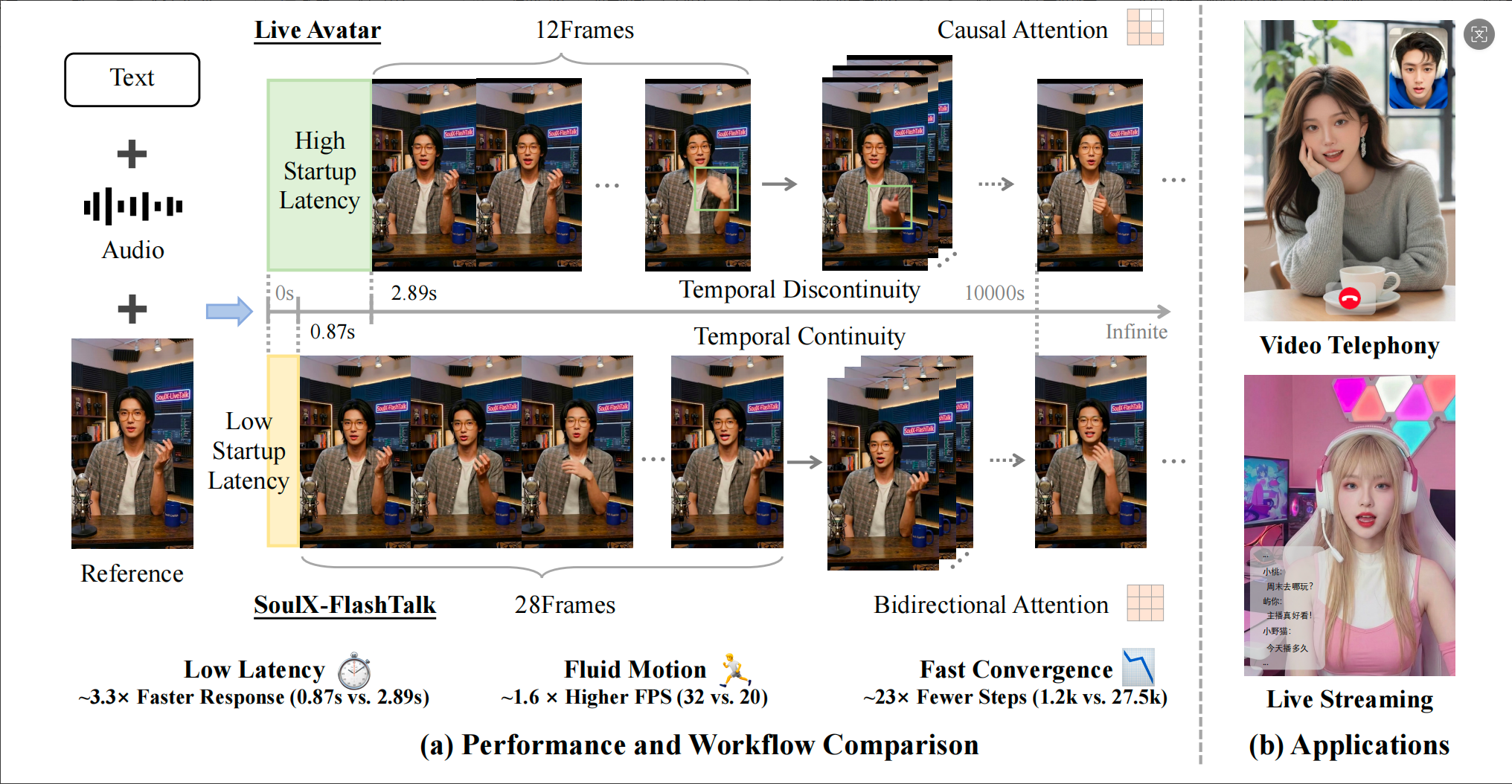
近期,Soul App AI團隊(Soul AI Lab)已開源實時數字人生成模型SoulX-FlashTalk 。這是首個能夠實現0.87s亞秒級超低延時、32fps高幀率,并支持超長視頻穩定生成的14B數字人模型。
在持續建設AI能力的過程中,Soul團隊始終致力于通過技術創新實現更沉浸、多元的交互體驗。此次開源新模型,除了在速度、效果、延遲和保真度上表現出色,更重要的是,為行業提供了切實可應用的業務解決方案,推動大參數量實時生成式數字人邁入可具體商用落地階段。
Project Page: https://soul-ailab.github.io/soulx-flashtalk/
Technical Report: https://arxiv.org/pdf/2512.23379
Source Code: https://github.com/Soul-AILab/SoulX-FlashTalk
HuggingFace:https://huggingface.co/Soul-AILab/SoulX-FlashTalk-14B
SoulX-FlashTalk亮點:
四大關鍵指標,重塑實時互動體驗
0.87s 亞秒級延時,即時交互
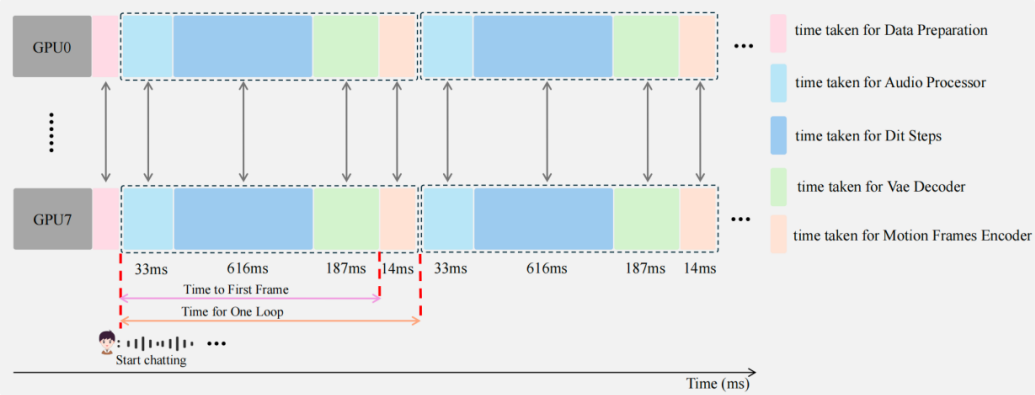
在實時視頻交互中,延遲是決定用戶體驗的核心。SoulX-FlashTalk 憑借全棧加速引擎的極致優化,成功將首幀視頻輸出的延時降至0.87s亞秒級。
?“零延遲”即時反饋: 首次讓 14B 級大模型數字人具備了即時反應能力,徹底消除了傳統大模型生成的“滯后感”。
?全場景交互: 無論是視頻通話中的即時對答、直播間彈幕的秒級互動,還是智能客服的實時響應,均能實現自然、流暢的深度對話。
32fps 高幀率,重新定義“流暢”
盡管搭載了 14B 參數量的超大 DiT 模型,SoulX-FlashTalk 的推理吞吐量仍高達 32 FPS。
?超越行業標準:遠超直播所需的 25 FPS 實時標準,確保每一幀畫面都絲滑順暢。
?大模型,高性能:證明了 140 億參數大模型在經過深度加速優化后,依然可以擁有極佳的運行效率。
超長視頻穩定清晰生成,告別畫面“崩壞”
數字人視頻最怕在生成中出現人物面部不一致或顯著畫質下降的問題。SoulX-FlashTalk 憑借獨家的自糾正雙向蒸餾技術,解決了這一痛點:
?無感糾錯,畫質無損:引入多步回溯自糾正機制,模擬長序列生成的誤差傳播并進行實時修正,就像為 AI 裝上了“實時校準器”,主動恢復受損特征。
?超長視頻,穩定生成: 不同于傳統的單向依賴,SoulX-FlashTalk 完全保留了雙向注意力機制,讓每一幀生成都能同時參考過去與隱含的未來上下文,從根本上壓制身份漂移,這意味著在超長直播中,主播的口型、面部細節和背景環境將始終保持一致,不會出現模糊或變形。
全身動作交互:不只是“口型對齊”
SoulX-FlashTalk 突破了傳統數字人僅能實現面部“對口型”的局限,帶來了更加真實自然的全身肢體動態表現。
?全身肢體動態合成: 不同于僅對臉部進行局部重繪的方案,SoulX-FlashTalk 支持受音頻驅動的全身動作生成,產生真實自然的人體動態。
?高精細手部表現: 基于14B DiT的強大建模能力,系統能夠有效消除手部畸形與運動模糊,精準呈現結構清晰、紋理銳利的手部動作細節。
?靈動而不失穩定: 在追求大幅度動態表現力的同時,系統依然維持了極高的身份一致性(Subject-C 達 99.22),實現了動作靈活性與畫面穩定性的完美平衡。
核心方案:
雙向蒸餾+多步回溯自糾正機制
在行業中,傳統數字人生成方案大多面臨畫面生成時間長、延遲高、生成效果差、效果不穩定、保真度低等問題。
在這樣的背景下,SoulX-FlashTalk正式開源,為了平衡生成質量與推理速度,團隊采用了兩階段訓練策略:
第一階段:延遲感知時空適配 (Latency-Aware Spatiotemporal Adaptation),結合動態長寬比分桶策略進行微調,使模型適應較低的分辨率和更短的幀序列;
第二階段:自糾正雙向蒸餾 (Self-Correcting Bidirectional Distillation)。利用 DMD 框架壓縮采樣步數并移除無分類器引導(CFG),實現加速;多步回溯自糾正機制,通過 autoregressively 合成連續分塊(最多 K個chunks),顯式模擬長視頻生成的誤差傳播;隨機截斷策略,在訓練中在第 k(< K)個分塊數進行反向傳播,實現高效且無偏的顯存友好優化。
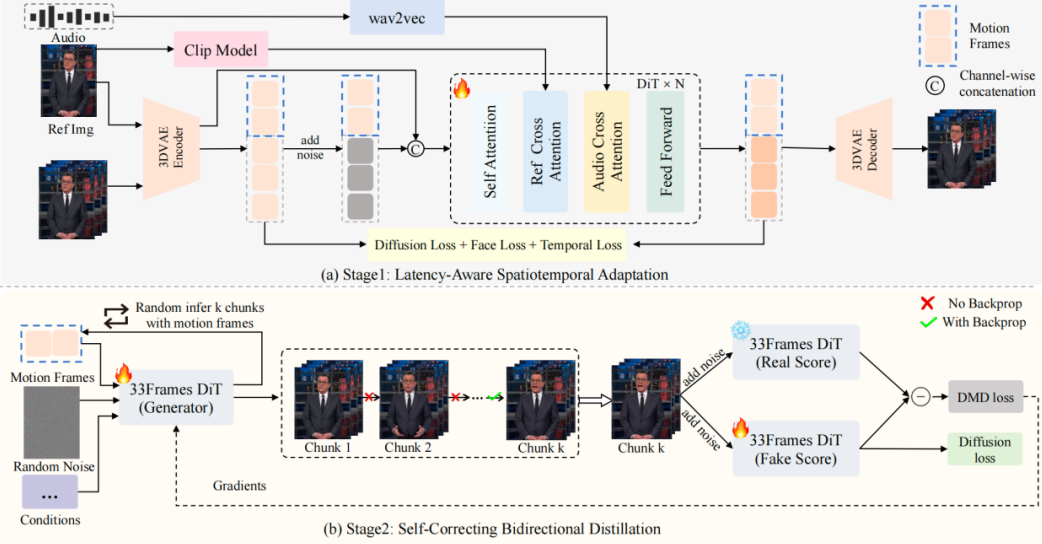
訓練流程示意圖
同時,團隊進行實時推理加速系統優化, 針對 8-H800 節點設計的全棧加速引擎實現了亞秒級延遲,包括了
?混合序列并行 (Hybrid Sequence Parallelism):整合 Ulysses 和 Ring Attention,使單步推理速度提升約5倍算子級優化:采用針對Hopper架構優化的FlashAttention3,通過異步執行進一步減少 20% 的延遲。
?3D VAE 并行化:引入空間切片并行解碼策略,實現VAE處理的5倍加速。
?整鏈優化:通過 torch.compile 實現全流程圖融合與內存優化。
值得注意的是,在Soul AI團隊發布的技術報告中指出,傳統的單向(Unidirectional)模型在處理全局時間結構時存在約束,容易導致時間不一致和身份漂移。因此,團隊完全保留雙向注意力機制(All-to-All 交互),使模型能同時利用過去與隱含的未來上下文,顯著提升了生成的一致性與細節質量。
SoulX-FlashTalk推理架構流程圖
AI+實時體驗
賦能行業多元業務場景
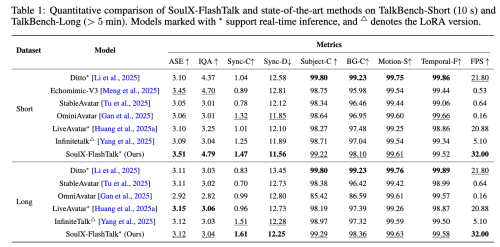
從模型表現來看,通過在 TalkBench-Short 和 TalkBench-Long 數據集上的定量對比,展示了SoulX-FlashTalk在視覺質量、同步精度及生成速度上的全面領先:
在短視頻評測中,它以3.51的ASE和4.79的IQA刷新了視覺保真度記錄,并以1.47的Sync-C分數表現出最優的口型同步精準度;在5分鐘以上的長視頻生成中,系統憑借雙向蒸餾策略有效抑制了同步漂移,取得了1.61的Sync-C優異成績;此外,作為14B參數規模的大模型,它在長短視頻任務中均維持了32 FPS 的高吞吐量,不僅遠超25 FPS的實時性基準,更在推理效率上顯著優于行業同類主流模型。
依托模型優越的性能表現,開源后,SoulX-FlashTalk將有機會在多領域、行業實際落地,創造更多價值。例如,在電商領域打造7×24小時AI直播間,特別是,此前傳統的數字人直播長時間運行后常會出現嘴型對不上或畫質模糊的問題,而SoulX-FlashTalk可以支持全天候的流暢視頻直播,即便是在高強度的實時互動中(如回復彈幕),也能保持如同真人出鏡的高保真畫質,極大降低直播成本。
此外,在短視頻制作、AI教育、多元互動場景NPC交互、AI客服等方向,模型也提供了高質量、可落地、可接入業務系統的解決方案。
對Soul而言,SoulX-FlashTalk的發布也意味著團隊進入了開源新階段。去年10月底,Soul AI團隊開源語音合成模型SoulX-Podcast,在發布后快速登頂開源社區平臺HuggingFace TTS(Text To Speech)趨勢榜,目前該模型在GitHub上收獲了超3100星標。
接下來,在聚焦語音對話合成、視覺交互等核心交互能力的提升,為用戶帶來更加沉浸、智能且富有溫度的交互體驗的過程中,以持續推進開源工作為契機,Soul將積極與全球開發者攜手,共建生態,為推動“ AI +社交”方向前沿能力建設貢獻力量。