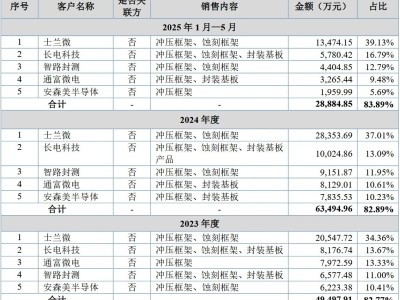
2月6日消息,美國時間2月5日上午,Anthropic與OpenAI相隔不到10分鐘先后發布了新一代旗艦模型——Claude Opus 4.6和GPT-5.3-Codex。
上午10點剛過,Anthropic率先扔出Claude Opus 4.6。官方的定義是“更聰明的模型”,強調其“規劃更謹慎、能更長時間持續執行代理式任務”。
幾乎就在同一時間,Sam Altman在X平臺上簡短而有力地宣布了GPT-5.3-Codex的登場。
兩家公司就像約好了一樣,在同一天同一時刻拋出了自己的重磅產品。這場“模型遭遇戰”背后,是兩大巨頭對于AI智能體技術路線的明確宣示。
GPT-5.3-Codex VS Claude Opus 4.6
基于官方信息,我們先看看兩款模型的定位與能力畫像。
1、GPT-5.3-Codex:從編碼助手到全能數字協作者
核心定位:
官方定義為“迄今為止能力最強的智能體編碼模型”,其目標是成為一個能完成開發者和專業人士在計算機上幾乎所有工作的智能體。
關鍵能力包括:
自我進化:首個在自身創建過程中發揮關鍵作用的模型,早期版本被用于調試自身訓練、管理部署和診斷評估結果。
網絡安全:被OpenAI自身歸類為網絡安全任務“高能力”模型,并首次直接訓練以識別軟件漏洞。為此,OpenAI配套推出了“可信網絡訪問”試點計劃和1000萬美元的API贈款計劃。
交互性:在工作時提供頻繁更新,允許用戶實時提問、討論方案并引導方向,如同協作的同事。
2. Claude Opus 4.6:深思熟慮的專業知識工作者
核心定位:在保持頂級安全性的前提下,于專業領域推理、長上下文處理及復雜任務規劃上實現突破。
關鍵能力包括:
超長上下文:首次為Opus級模型推出100萬token的上下文窗口(測試版)。在“大海撈針”測試中,其信息召回率從上一代的18.5%躍升至76%,實現了質的提升。
可控的智能:新增“effort”(努力)控制參數(低、中、高、最高),讓開發者能在成本、速度和質量間取得平衡;并引入“自適應思考” 功能,讓模型能根據任務難度自行調整思考深度。
專業領域卓越:在衡量金融、法律等領域知識工作的GDPval-AA評估中,其Elo評分比業內第二的模型(GPT-5.2)高出約144分。
以下表格整合了官方數據,直觀展示二者的性能特征:
簡單來說,如果你的工作像一名需要沖鋒陷陣、在終端和各類工具中穿梭的“特種兵”,GPT-5.3-Codex 的交互性和執行力更強。
如果你的任務更像是一位需要審慎研究、處理海量資料并做出專業決策的“分析師”或“架構師”,Claude Opus 4.6 的深度和可靠性更優。
OpenAI和Anthropic路線分道揚鑣?
雖然各有側重,但兩款模型的升級,共同指向并加速了同一個未來:AI智能體(Agent)的普及化。但它們選擇從不同路徑切入。
GPT-5.3-Codex將智能體的能力從“寫代碼”擴展到“運行并維護整個軟件生命周期”,這意味著未來軟件項目的開發、調試、部署、監控可能由AI智能體串聯完成。Claude Opus 4.6則能自主管理大型代碼庫遷移、分配任務,扮演“技術主管”角色。
兩者都深度融合了辦公套件。Claude已推出Excel增強版和PowerPoint研究預覽;GPT-5.3-Codex可根據模糊指令生成功能完備的網站和演示文稿。這標志著AI開始理解工作流背后的業務意圖,而不僅僅是執行單一指令。
值得注意的是,兩者均在網絡安全能力上大幅提升,迫使行業進入新階段。OpenAI配套推出了防御性工具和贈款計劃,Anthropic也強調用AI幫助修補漏洞。這預示著AI將成為攻防兩端的關鍵工具,生態建設(如為開源項目提供免費安全掃描)變得至關重要。
另一個值得關注的趨勢是,GPT-5.3-Codex“自我用于開發”的實踐具有里程碑意義,模型開發進入“自舉”新階段。這不僅是效率提升,更可能開啟AI自我迭代優化的新范式,進一步加速技術進化速度。
此次發布并非簡單的功能迭代,而是兩大巨頭關于AI未來形態的一次路線展示。
OpenAI的路線是“擴張與融合”,讓Codex成為一個能操作計算機、打通所有數字任務的通用智能體底座,追求能力的廣度與交互的自然度。
Anthropic的路線是“深化與可控”,在確保安全與可靠的前提下,將模型打造為在特定專業領域(金融、法律、編碼)具有頂級深度分析能力的“專家”,并賦予開發者精細的控制權。
無論哪條路線,我們都在見證一個根本性轉變:AI正從一個需要被“提示”的工具,轉變為一個可以自主規劃、執行復雜任務、并能與人實時協作的智能體。這不僅僅會改變開發者和知識工作者的工作方式,最終將重新定義軟件、服務乃至整個數字生態的構建方式。
而競爭的下一個前沿,將是這些智能體如何被安全、高效、大規模地集成到真實世界的業務流程中。