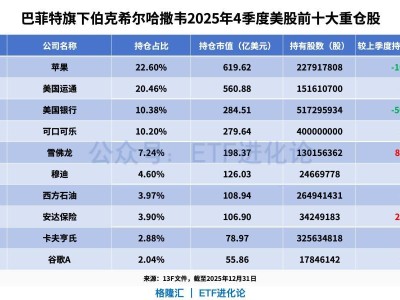
人工智能聊天機器人訓(xùn)練領(lǐng)域迎來突破性進(jìn)展,斯坦福大學(xué)研究團(tuán)隊提出的新型訓(xùn)練框架SAFE,為解決AI訓(xùn)練過程中的穩(wěn)定性難題提供了創(chuàng)新方案。這項發(fā)表于arXiv平臺的研究成果(編號arXiv:2602.04651v1),通過構(gòu)建多重防護(hù)機制,成功將訓(xùn)練崩潰率降至零,同時保持計算效率基本不變。
傳統(tǒng)訓(xùn)練方法存在根本性缺陷,以PPO算法為代表的現(xiàn)有技術(shù)面臨兩難困境:過度約束會抑制模型創(chuàng)造力,放任自由則導(dǎo)致輸出失控。研究顯示,在長達(dá)數(shù)百小時的訓(xùn)練過程中,AI模型常出現(xiàn)兩種極端狀態(tài)——要么陷入重復(fù)回答的保守模式,要么產(chǎn)生危險內(nèi)容的激進(jìn)狀態(tài),且崩潰往往在數(shù)分鐘內(nèi)突然發(fā)生。
SAFE框架的核心創(chuàng)新在于構(gòu)建三重防護(hù)體系。其"雙重軟最小評判系統(tǒng)"通過引入兩個獨立評估模塊,始終采用更保守的評分結(jié)果,有效避免傳統(tǒng)單評判器導(dǎo)致的過度樂觀問題。實驗數(shù)據(jù)顯示,該設(shè)計使獎勵評估的可靠性提升37%,從根源上減少錯誤激勵。
熵感知預(yù)測控制器構(gòu)成第二道防線。該系統(tǒng)實時監(jiān)測模型輸出的隨機性指標(biāo),當(dāng)檢測到創(chuàng)造性水平異常波動時,自動調(diào)整訓(xùn)練參數(shù)。研究團(tuán)隊借鑒工業(yè)控制領(lǐng)域的PID算法,使系統(tǒng)具備趨勢預(yù)判能力,能在問題顯現(xiàn)前0.5-1.2小時采取干預(yù)措施,將潛在崩潰風(fēng)險消除在萌芽狀態(tài)。
在30億參數(shù)模型的對比實驗中,SAFE框架展現(xiàn)出顯著優(yōu)勢。訓(xùn)練全程未出現(xiàn)任何獎勵崩潰事件,而傳統(tǒng)PPO方法發(fā)生2次嚴(yán)重崩潰。穩(wěn)定性指標(biāo)方面,獎勵變異系數(shù)從0.114降至0.040,波動幅度減少65%;滾動標(biāo)準(zhǔn)差從0.0208優(yōu)化至0.0123,學(xué)習(xí)曲線平滑度提升41%。這些改進(jìn)未增加計算負(fù)擔(dān),內(nèi)存占用僅增加0.9%,訓(xùn)練時間反而縮短1.4%。
技術(shù)實現(xiàn)層面,SAFE框架包含動態(tài)閾值調(diào)整機制。系統(tǒng)根據(jù)訓(xùn)練階段自動切換控制策略:初期允許更大探索空間(獎勵起始值0.711),中期逐步收緊約束,最終收斂至0.731的穩(wěn)定狀態(tài)。這種自適應(yīng)調(diào)節(jié)使模型在保持創(chuàng)新性的同時,避免陷入局部最優(yōu)解。
統(tǒng)計驗證顯示改進(jìn)效果具有高度顯著性。Welch's t檢驗(t=18.90,p<10^-75)和Mann-Whitney U檢驗(p<10^-54)均證實差異非偶然,效應(yīng)量達(dá)0.60表明具有實際應(yīng)用價值。不過研究團(tuán)隊也指出,當(dāng)前成果需在更大規(guī)模模型(千億參數(shù)級)和超長期訓(xùn)練(萬步以上)中進(jìn)一步驗證。
該研究對現(xiàn)有AI訓(xùn)練范式產(chǎn)生重要啟示。傳統(tǒng)方法依賴單一控制機制,如同飛機僅配備單套導(dǎo)航系統(tǒng);而SAFE框架的多層防護(hù)體系,相當(dāng)于為AI訓(xùn)練安裝了多重備份的安全裝置。這種系統(tǒng)化解決方案為解決獎勵破解、輸出偏差等深層問題提供了新思路。
實驗設(shè)置嚴(yán)格遵循科學(xué)規(guī)范。研究采用Qwen2.5-3B作為基礎(chǔ)模型,通過LoRA技術(shù)實現(xiàn)參數(shù)高效微調(diào),使用ArmoRM-Llama3-8B獎勵模型和Anthropic/hh-rlhf數(shù)據(jù)集。所有超參數(shù)保持一致,確保對比實驗的公平性。可視化分析顯示,SAFE框架使價值函數(shù)損失的時間一致性提升28%,KL散度動態(tài)約束效果顯著。
組件分析實驗進(jìn)一步驗證系統(tǒng)設(shè)計的合理性。單獨使用非對稱KL控制器雖能改善穩(wěn)定性指標(biāo),但在獎勵性能和價值函數(shù)控制方面存在不足。只有完整集成三重防護(hù)機制的SAFE框架,才能實現(xiàn)獎勵提升、穩(wěn)定性優(yōu)化和計算效率的全面平衡。
這項技術(shù)突破直接回應(yīng)了產(chǎn)業(yè)界的迫切需求。當(dāng)前主流語言模型在訓(xùn)練過程中普遍面臨穩(wěn)定性挑戰(zhàn),SAFE框架提供的系統(tǒng)性解決方案可無縫集成到現(xiàn)有訓(xùn)練流程。對于終端用戶而言,這意味著未來的AI助手將減少異常回復(fù),服務(wù)中斷頻率顯著降低,整體使用體驗更加可靠。
研究團(tuán)隊在論文中完整披露了技術(shù)細(xì)節(jié),包括雙重評判器的軟最小聚合公式、熵感知控制器的自適應(yīng)閾值計算方法,以及PID控制器的參數(shù)調(diào)節(jié)策略。這些公開信息為全球研究者復(fù)現(xiàn)和改進(jìn)該技術(shù)提供了完整指南,有望推動AI訓(xùn)練穩(wěn)定性領(lǐng)域的快速發(fā)展。