近日,稀宇科技正式發布其最新模型minimax m2.5,引發人工智能社區廣泛關注。這款模型在復雜場景下的表現突破,得益于背后一套名為forge的異步原生agent強化學習系統。該系統通過創新架構設計和工程優化,成功解決了大規模強化學習中的多個關鍵難題。
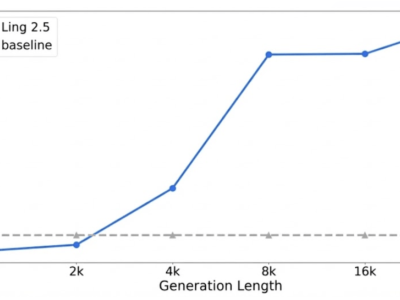
在真實世界的大規模應用中,強化學習系統需要同時滿足系統吞吐量、訓練穩定性與agent靈活性三方面的要求。傳統框架往往難以平衡這些需求,而forge系統通過標準化agent-LLM交互協議,支持對任意agent架構進行訓練。該系統實現了每天百萬級樣本量的處理能力,在200k上下文長度下仍能保持穩定的性能提升。
系統設計方面,forge采用模塊化架構,將agent執行邏輯與底層訓推引擎徹底解耦。核心模塊包括agent抽象層、中間件抽象層和訓練推理引擎。其中,中間件包含標準化通信網關和分布式數據存儲,有效隔離了底層模型復雜性與高層行為邏輯。訓練引擎則通過rollout引擎和train引擎的協同工作,確保模型使用最新策略分布進行探索。
針對白盒agent的特殊需求,研發團隊將上下文管理機制直接整合到強化學習交互循環中。通過將上下文變遷建模為環境動態的一部分,解決了長程任務中常見的注意力稀釋問題。實驗數據顯示,這種設計顯著提升了模型在深搜索等復雜任務中的表現,同時保持了訓練與推理階段的數據分布一致性。
對于閉源黑盒agent,系統采用非侵入式集成方案。通過標準化網關接收請求,無需了解內部實現細節即可完成數據收集和訓練。這種設計使系統能夠廣泛適配各類agent架構,包括代碼agent和采用激進上下文縮減策略的agent。測試表明,該方法在完全不透明的系統中仍能帶來穩定的性能提升。
工程優化方面,團隊提出windowed fifo調度策略,在吞吐量與數據分布一致性間取得平衡。該策略通過設置可見窗口,既避免了隊頭阻塞,又防止訓練分布向簡單樣本偏移。針對多輪請求中的前綴冗余問題,開發的prefix tree merging方案將訓練樣本重構為樹形結構,實現約40倍的訓練加速并降低顯存消耗。
在推理加速領域,系統采用dynamic mtp技術,并通過top-k kl損失保持與rl策略的對齊。通過pd分離設計和全局l3 kv緩存池,進一步優化了長尾樣本延遲和緩存命中率。這些創新使rollout階段的算力占比降至60%,同時保持了高水平的模型接受率。
算法層面,研發團隊設計了復合獎勵機制來解決超長軌跡的信用分配問題。該機制包含過程獎勵、任務完成時間獎勵和后續獎勵三部分,通過提供密集反饋和標準化回報,顯著提高了訓練穩定性。這種設計使模型能夠主動優化執行路徑,在保持性能的同時提升響應速度。
目前,minimax m2.5模型已全面開源,開發者可通過hugging face和github平臺獲取相關資源。這一發布為人工智能社區提供了新的研究基準,其創新架構和工程實踐為大規模強化學習應用樹立了新的典范。