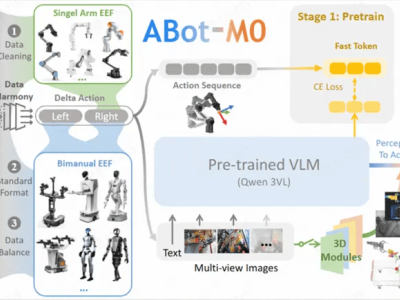
在自動駕駛與機器人控制等高風險領域,強化學習技術正面臨關鍵挑戰:如何在保證絕對安全的前提下實現高效控制。清華大學研究團隊近期提出創新算法,通過引入"主動探索危險邊界"機制,成功破解了安全強化學習領域長期存在的核心矛盾,在權威測試平臺刷新多項性能紀錄。
傳統安全強化學習算法普遍采用"被動防御"策略,通過嚴格限制智能體行動范圍來避免違規。但研究團隊發現,這種過度保守的設計反而導致系統陷入惡性循環——隨著安全約束加強,違規樣本數量急劇減少,使得系統對危險邊界的認知變得模糊。實驗數據顯示,當違規率降至0.1%以下時,可行性函數的估計誤差會呈指數級增長,最終引發安全性崩塌。
針對這一困境,研究團隊開發出雙策略架構的RACS算法。該系統包含兩個協同工作的智能體:"執行者"負責在安全范圍內優化任務表現,"探險者"則專門觸碰安全邊界以收集關鍵數據。這種設計巧妙利用對抗性探索機制,在保持總采樣量不變的情況下,使違規樣本占比提升10-100倍,顯著改善了系統對危險狀態的判斷精度。
技術實現層面,研究團隊采用重要性采樣技術解決雙策略數據分布差異問題,并通過KL散度約束確保訓練穩定性。在Safety-Gymnasium基準測試中,該算法在14項復雜任務中同時實現安全指標與任務性能的雙重領先。特別是在高維度HumanoidVelocity任務中,RACS不僅達成零違規,其任務回報率較傳統方法提升23%,推箱子導航任務的成功率更是提高41%。
深入分析顯示,算法性能提升源于三個關鍵改進:危險狀態采樣量增加一個數量級、可行性函數估計誤差降低82%、風險低估頻率減少94%。這意味著系統能更準確識別潛在危險,從根本上避免了因認知模糊導致的意外違規。在HalfCheetahVelocity等任務中,該算法甚至實現了連續百萬步零違規的突破性表現。
這項研究為安全強化學習的實際應用開辟了新路徑。通過將"主動認知危險"理念融入算法設計,有效解決了高風險場景中安全與性能的平衡難題。相關代碼已在開源平臺公開,其雙策略架構與對抗性探索機制為工業界提供了可直接借鑒的技術方案,特別是在自動駕駛決策系統開發中具有重要應用價值。