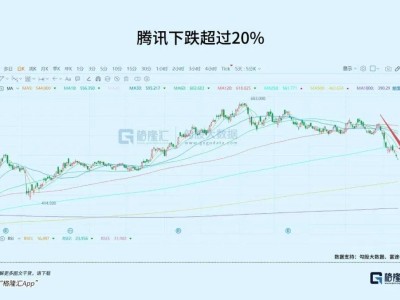
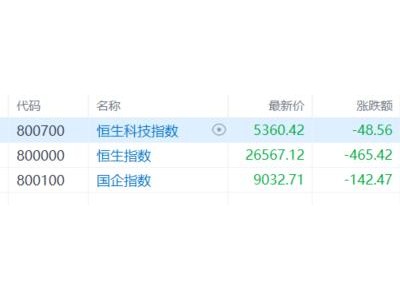
智譜公司近日正式推出并開源了其最新研發的GLM-OCR模型,該模型以0.9B的輕量化參數規模,在文檔識別領域展現出強勁實力。模型支持vLLM、SGLang和Ollama等多種部署框架,在公式識別、表格解析及信息抽取等核心任務中均達到行業領先水平,多項基準測試成績刷新最優紀錄。
針對實際應用場景的多樣化需求,研發團隊對手寫體識別、復雜表格解析、代碼文檔處理、印章檢測及多語言混排等特殊場景進行了深度優化。在效率測試中,該模型處理PDF文檔的吞吐量達到每秒1.86頁,通過API調用服務的定價為每百萬Tokens僅需0.2元,兼具性能與成本優勢。
技術架構方面,GLM-OCR采用"編碼器-解碼器"雙階段設計,集成自主研發的CogViT視覺編碼器,創新性地構建"版面分析→并行識別"的技術流程。這種設計使模型能夠同時處理多個識別任務,顯著提升復雜文檔的處理效率。目前,完整的軟件開發工具包(SDK)與推理工具鏈已同步開源,特別適用于需要高并發處理或邊緣計算的場景。
該模型的開源策略引發行業廣泛關注,其提供的完整技術方案不僅降低了企業應用門檻,更為學術研究提供了重要參考。通過開放核心代碼與工具鏈,智譜團隊為文檔智能化處理領域注入了新的發展動力,推動相關技術向更高效、更普惠的方向演進。