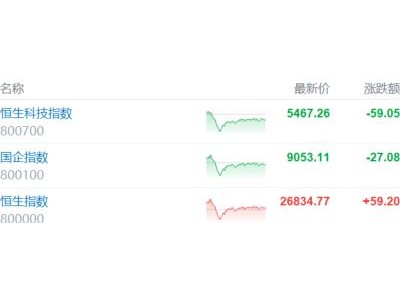
在強化學習領域,超大模型的訓練與部署長期面臨顯存容量與通信效率的雙重挑戰。近期,由多支技術團隊聯合攻關的INT4量化感知訓練(QAT)方案取得突破性進展,成功將1TB級模型壓縮至單張H200顯卡(141GB顯存)內運行,在保持訓練穩定性的同時,顯著提升了Rollout效率。
該方案創新性地采用"訓練端偽量化+推理端真實量化"的組合策略。訓練階段通過插入量化-反量化操作模擬低精度計算,利用STE梯度直通技術解決量化不可導問題,確保模型在BF16主權重基礎上適應INT4精度分布。推理階段則采用W4A16(INT4權重×BF16激活)混合精度計算,通過動態打包技術將8個INT4數值壓縮至單個INT32存儲,在保持數學等效性的同時減少75%內存占用。
技術實現層面,研究團隊對Megatron-LM框架進行深度改造。在前向傳播中,基于分組最大絕對值動態量化技術,將權重范圍約束在[-7,7]區間;反向傳播時通過定制化Kernel實現梯度無損傳遞。針對MoE模型特性,開發了動態塊對齊算法,根據Token分布自動優化專家計算單元的顯存利用率,使帶寬效率提升40%以上。
實驗數據顯示,在dapo-math-17k數據集上,采用INT4推理的Qwen3-235B模型與BF16基線相比,原始獎勵值(Raw-Reward)增長曲線高度吻合,AIME基準測試評分差異控制在0.3%以內。更關鍵的是,通過顯存壓縮實現的單機部署方案,使跨節點通信開銷歸零,在235B參數規模下,Rollout階段吞吐量較FP8方案提升18%,較基礎BF16方案提升32%。
該成果在開源社區引發廣泛關注,其核心價值體現在三個方面:首先突破硬件限制,通過極致量化使單機承載模型參數規模提升一個數量級;其次實現訓推全流程精度對齊,消除傳統量化方案中常見的分布偏移問題;最后構建了完整的工具鏈,支持GPTQ、AWQ等多種量化格式的無縫轉換,兼容對稱/非對稱量化模式。
技術團隊透露,當前方案在訓練階段仍存在約15%的性能損耗,主要源于偽量化操作的額外計算開銷。后續優化將聚焦于訓練Kernel的融合重構,計劃通過算子合并與并行化改造,將QAT訓練效率提升至BF16模式的90%以上。同時,隨著NVIDIA Blackwell架構的普及,團隊正探索FP4量化在強化學習場景的應用潛力,預計可在現有基礎上進一步壓縮50%顯存占用。