當你在旅行中用手機翻譯軟件快速獲取餐廳菜單的中文解釋,或在跨國會議中依賴實時翻譯工具理解外籍同事的發(fā)言時,或許不會意識到,這些看似成熟的AI技術,在處理學術論文、法律合同或技術手冊等專業(yè)長文檔時,仍面臨巨大挑戰(zhàn)。字節(jié)跳動種子實驗室與北京大學聯(lián)合發(fā)布的最新研究,通過構建全球首個長文檔專業(yè)翻譯評估基準DiscoX和配套的Metric-S智能評估系統(tǒng),首次揭示了當前AI翻譯技術在真實專業(yè)場景中的能力邊界。
研究團隊在構建DiscoX基準的過程中,展現(xiàn)了近乎苛刻的嚴謹性。他們邀請133位專業(yè)人士參與,包括115名各領域專家和18名資深語言學家,歷時1330個人工小時,從665個初始文本中篩選出200個高質量測試案例。這些案例覆蓋學術論文、法律文件、技術手冊、新聞報道和文學作品等七個專業(yè)領域,平均長度達1712個詞,是傳統(tǒng)評估基準文本長度的近30倍。這種設計確保了評估能夠真實反映專業(yè)翻譯中術語一致性、邏輯連貫性和風格統(tǒng)一性等核心挑戰(zhàn)。
Metric-S智能評估系統(tǒng)的創(chuàng)新在于其多維度的評估框架。該系統(tǒng)模擬專業(yè)翻譯評審流程,設置"準確性""流暢性""適當性"三個評審團,分別檢查譯文是否忠實傳達原文含義、是否符合目標語言習慣、是否保留原文風格特征。通過獨特的"去重和歸因"機制,系統(tǒng)能夠識別錯誤之間的因果關系,避免對同一根本錯誤重復扣分。測試顯示,Metric-S與人類專家判斷的一致性達到70.3%,較現(xiàn)有自動評估系統(tǒng)提升一倍以上,且能提供詳細的錯誤分析和改進建議。
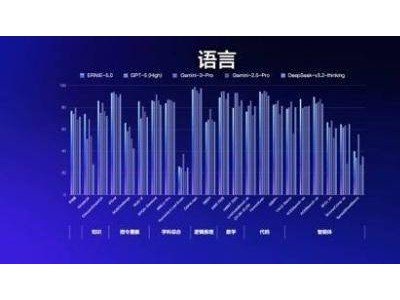
在對20個主流AI翻譯系統(tǒng)的測試中,研究團隊發(fā)現(xiàn)了令人深思的結果。即使是最先進的GPT-5-high系統(tǒng),綜合得分僅為76.66分,仍落后于人類專家的80.16分。不同系統(tǒng)展現(xiàn)出鮮明的"個性特征":GPT-5-high在準確性上表現(xiàn)突出,但流暢性稍顯生硬;Kimi-K2語言流暢自然,卻偶爾出現(xiàn)準確性瑕疵;Claude-4系列則呈現(xiàn)準確性尚可但流暢性不足的特點。更意外的是,所謂"思考增強型"模型如Qwen-3-235B的思考版本,得分反而比普通版本低近10分,顯示出過度分析可能導致的性能下降。
測試結果還揭示了AI翻譯系統(tǒng)的系統(tǒng)性短板。所有系統(tǒng)在中文翻譯成英文方面的表現(xiàn)普遍優(yōu)于反向翻譯,反映出訓練數(shù)據(jù)的不平衡和模型架構的英語偏向性。在專業(yè)領域適應性上,學術論文翻譯表現(xiàn)最佳,而文學作品翻譯明顯吃力,暴露出AI在處理復雜修辭、文化內涵和情感表達方面的不足。傳統(tǒng)機器翻譯系統(tǒng)和特定領域優(yōu)化系統(tǒng)表現(xiàn)更差,在處理長文檔時經(jīng)常出現(xiàn)內容混亂和信息遺漏等問題。
這項研究的技術價值遠不止于評估工具的創(chuàng)新。DiscoX和Metric-S的開源發(fā)布,為全球翻譯技術研發(fā)提供了統(tǒng)一的衡量尺度。企業(yè)現(xiàn)在可以基于科學標準選擇和評估翻譯服務,開發(fā)者也能獲得明確的改進方向。對于翻譯行業(yè)從業(yè)者,研究既證明了專業(yè)譯員在處理復雜文檔時的不可替代性,也指出了語篇連貫性、術語一致性等需要重點提升的能力領域。
從更宏觀的視角看,這項研究反映了AI技術發(fā)展的一個重要轉向:從追求單項指標突破轉向關注綜合應用能力。就像自動駕駛技術需要處理復雜交通環(huán)境而非僅識別交通標志,翻譯技術的真正進步在于處理長篇、專業(yè)、復雜文檔的綜合能力。這種評估理念的變革,預示著未來AI系統(tǒng)將更加注重實際應用場景的復雜性和專業(yè)性要求,為整個AI行業(yè)的發(fā)展提供了重要啟示。