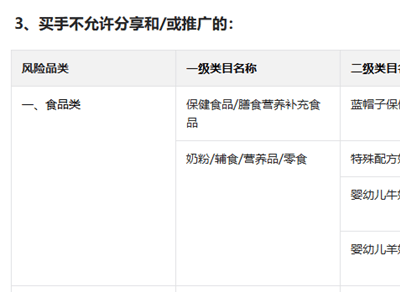
字節(jié)跳動旗下AI產(chǎn)品豆包與即夢近日完成重大技術(shù)升級,正式接入全新視頻生成模型Seedance2.0。該模型突破傳統(tǒng)創(chuàng)作模式,支持圖像、視頻、音頻、文本四模態(tài)輸入,用戶可通過組合不同媒介精準控制生成內(nèi)容。目前豆包App、電腦端、網(wǎng)頁版及即夢全平臺均已開放體驗,其中移動端版本更推出真人數(shù)字分身功能,用戶完成面部生物特征校驗后即可創(chuàng)建個性化虛擬形象參與視頻創(chuàng)作。
在交互設(shè)計方面,Seedance2.0實現(xiàn)創(chuàng)作邏輯的顛覆性革新。創(chuàng)作者可上傳特定風格圖片設(shè)定視覺基調(diào),導入視頻片段規(guī)范角色動作軌跡,甚至通過音頻波形控制畫面節(jié)奏與氛圍渲染。這種多模態(tài)參考機制使"提示詞"不再局限于文字指令,顯著降低專業(yè)視頻制作門檻。測試數(shù)據(jù)顯示,該模型在角色一致性、運動合理性等核心指標上達到行業(yè)領(lǐng)先水平,生成效率較前代提升40%以上。
針對隱私保護與倫理規(guī)范,平臺采取差異化運營策略。移動端應(yīng)用在啟用真人分身功能前,強制要求用戶完成動態(tài)活體檢測,確保生物特征數(shù)據(jù)采集符合安全標準。而電腦端及網(wǎng)頁版則明確禁止上傳真實人臉素材,僅支持通過系統(tǒng)內(nèi)置虛擬形象庫進行創(chuàng)作。這種分層防護機制既滿足個性化需求,又有效規(guī)避潛在風險。
此前Seedance2.0已完成三個月封閉測試,其多模態(tài)理解能力與精準控制特性引發(fā)全球創(chuàng)作者關(guān)注。內(nèi)測期間,該模型成功生成超過200萬條高質(zhì)量視頻內(nèi)容,涵蓋影視短片、廣告創(chuàng)意、教育課件等多個領(lǐng)域。技術(shù)團隊透露,后續(xù)版本將持續(xù)優(yōu)化3D空間建模與物理引擎模擬能力,進一步拓展專業(yè)創(chuàng)作場景的應(yīng)用邊界。