對于大模型,OpenAI、Anthropic、谷歌等全球頂尖的AI公司,都在不斷地強調模型的通用性,以及其涌現能力。可字節在豆包2.0上,卻來了一波“反向操作”。
字節跳動選擇了一條更務實的路徑。他們從真實業務場景倒推模型能力。
豆包團隊發現,企業用戶最高頻的需求不是解奧數題,而是處理混雜著圖表、文檔的非結構化信息,然后在這個基礎上完成多步驟的專業任務。
于是豆包2.0把優化重點放在了多模態理解、長上下文處理、指令遵循這些“不那么性感但很實用”的能力上。
這種路徑選擇可能更接近AGI的本質。
真正的通用智能不是在所有基準測試上都拿高分,而是能在真實世界各種雜七雜八的約束下,依然按要求完成任務。
一個能解IMO金牌題但無法完成企業報表分析的模型,和一個可以穩定完成業務流程的模型,哪個更“智能”?
豆包2.0的答案很明確。
我把這段話發給了豆包2.0,它回答我說
雖然有些阿諛奉承、迎風拍馬,但我們的觀點是相似的。
01
豆包2.0來了
就在2026年情人節這天,豆包更新了2.0版本。PC、網頁版、手機用戶都可以從對話框選擇“專家”模式,以開啟豆包2.0。
與此前版本相比,豆包2.0的核心變化在于從“能解題”轉向“能做事”——針對大規模生產環境的使用需求進行了系統性優化。
豆包2.0系列包含Pro、Lite、Mini三款通用Agent模型和一款 Code 模型。
豆包2.0Code 接入了AI編程產品TRAE,而火山引擎也同步上線了豆包2.0系列模型API服務。
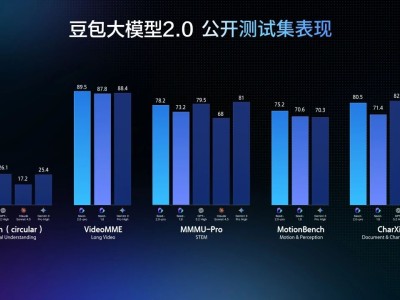
從公開的基準測試數據來看,豆包2.0 Pro在多個維度上取得了有競爭力的成績。
豆包2.0在IMO、CMO 數學競賽和ICPC編程競賽中獲得金牌成績,在 Putnam基準測試上超越了Gemini 3 Pro。
在HLE-Text(人類的最后考試)這項綜合性評測中,豆包2.0 Pro得分54.2,在參與對比的模型中排名第一。
不過需要注意的是,基準測試成績與實際應用表現之間存在差異。
字節跳動團隊自己也承認,豆包2.0在端到端整體代碼生成、上下文學習等方面,與國際領先模型相比仍有提升空間。
這種坦誠的表態,比單純強調優勢更有說服力。
在科學領域知識測試中,豆包2.0的表現與Gemini 3 Pro和GPT-5.2處于同一水平線。
在SuperGPQA測試中,豆包2.0 Pro得分68.7,略高于GPT-5.2的67.9。在HealthBench測試中得分57.7,排名第一。
這些數據表明,相較于豆包1.8,新版本的豆包在長尾領域知識覆蓋上有所加強。
豆包2.0在多模態理解上的提升是全方位的。
在視覺推理方面,模型在MathVista、MathVision等基準上達到了業界最優水平。
這些考試比簡單的圖像識別要復雜得多。
因為這些測試的目的,是考察模型能否從圖像中提取數學關系、理解幾何結構、進行邏輯推演。
在文檔理解場景中,豆包2.0在ChartQA Pro與OmniDocBench 1.5基準上的表現達到頂尖水平。
現實中的文檔往往是表格、圖表、文字、公式混雜的復雜版式,模型需要準確識別結構、提取信息、理解關系。
在長上下文理解方面,豆包2.0在 DUDE、MMLongBench等測試中取得了較好成績。
視頻理解是豆包2.0的一個重點優化方向。
在TVBench、TempCompass、MotionBench等測試中,豆包2.0處于領先位置。
值得注意的是,在EgoTempo基準上,豆包2.0的得分超過了人類水平。這個細節說明,模型在捕捉“變化、動作、節奏”這類時序信息時,可能比人類更穩定.
豆包2.0還支持流式實時視頻分析,可以實現環境感知、主動糾錯與交互。這種能力的應用場景包括健身指導、穿搭建議等,模型能實時觀察并給出反饋,而不是事后分析錄像。
02
豆包團隊如何實現?
其實豆包2.0的這些提升背后,涉及到了多個層面的優化。
多模態融合架構的改進是基礎。
傳統的多模態模型是把視覺編碼器和語言模型簡單拼接,視覺信息和文本信息的交互深度不夠。
豆包2.0強化了視覺與語言的深度融合,讓模型能更好地理解圖像中的語義信息。
人類看一張圖,它是包含因果關系的。
就拿這張圖來說,傳統多模態大模型看到這張圖,它理解的是“姚順宇”、“話筒”、“手”、“西裝”。
但是人類理解這張圖是“姚順宇西裝革履拿著話筒正在演講”。
即使圖片是靜態的,也能因為他的神態、穿著來判斷此時正在做什么。
豆包2.0對注意力機制的改進,為它帶來了長上下文處理能力的提升。
處理長文本或長視頻時,模型需要在海量信息中保持注意力,不能顧此失彼。
就比如你在閱讀這篇文章的時候,A部分出現了大量的技術名詞、術語,你也只會挑其中的圖片以及數字來一目十行地看,不會逐字逐句認真看。
因此豆包2.0其實是以人類讀長文章時那樣,自動抓重點,而不是平均分配注意力。
技術上,這需要更高效的注意力計算方法和更合理的信息篩選機制。
最后,豆包2.0推理能力的提升不只是記住更多知識,而是真正提升了從已知推導未知的能力。
這涉及到訓練過程中對推理鏈的顯式建模,讓模型學會“一步步思考”而不是直接給答案。這種能力在解決復雜問題時尤為重要。
03
現實不是競賽
字節跳動團隊觀察到一個現象,語言模型已經可以順利解決競賽難題,但放在真實世界中,它們依然很難端到端地完成實際任務。
比如一次性構建一個設計精良、功能完整的小程序。
這個鴻溝的原因主要有兩點,第一是知識覆蓋的問題。
競賽題目通常聚焦在數學、編程等核心領域,而真實任務往往涉及長尾領域的專業知識,比如前文提到的醫療、法律、工程、商業等等。
第二是指令遵循的問題。
真實任務通常包含多個步驟、多重約束,模型需要嚴格按照要求一步步推進,不能跑偏,不能遺漏。
豆包2.0試圖通過系統性加強長尾領域知識和強化指令遵循能力來彌合這個鴻溝。
從測試數據來看,在深度研究任務、復雜agent能力評估等方面,豆包2.0達到了業界第一梯隊水平。
在客服問答、信息抽取、意圖識別等高頻應用場景上,模型表現也比較穩定。
播客中給出了一個有意思的案例——高爾基體蛋白分析。
豆包2.0不僅能給出總體實驗路線,還能把基因工程、小鼠模型構建、亞細胞分離與多組學分析串成完整流程,細化到關鍵環節怎么做、用什么進行對照、用哪些指標評估純度。
相關領域專家表示,這個方案在跨學科的實驗細節與步驟化表達上,超出了他們對大模型的預期。
不過,從“能給出方案”到“方案真正可行”,中間還有驗證的距離。這個案例更多說明模型在知識整合和表達能力上的進步,而不是說它已經能替代科研人員做實驗設計。
眾所周知,AI編程是2026年最火的賽道,豆包2.0 Code是針對編程場景優化的版本,已上線TRAE作為內置模型。
字節團隊展示的案例是“TRAE春節小鎮·馬年廟會”互動項目。通過1輪提示詞構建基本架構,再經過幾次調試,總共5輪提示詞完成作品。
這個小鎮里有11位由大語言模型驅動的NPC,會根據人設自然聊天、招呼顧客、現場砍價。
AI游客自己決定去哪家攤位、買什么、說什么。
其中,煙花升空時的祝福語、孔明燈上的題詞都由AI即時生成。每次進入小鎮,看到的互動都可能不同。
這個案例展示了豆包2.0 Code模型在快速原型開發上的能力。不過需要注意的是,從原型到產品之間還有很長的路要走。
從字節跳動的策略來看,豆包2.0強調“面向真實世界復雜任務”,這是一個務實的定位。
通過分析真實使用場景來指導模型優化,而不是單純為了刷榜。
這種以需求為導向的研發思路,可能比單純追求基準測試分數更有價值。