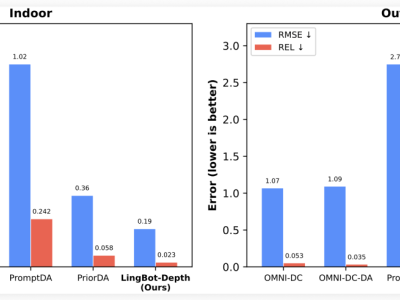
人工智能在語言理解領域長期面臨一個核心難題:現(xiàn)有技術能識別詞語間的關聯(lián),卻難以準確判斷這些關聯(lián)是同義、反義還是一般相關。土耳其多家科研機構聯(lián)合攻關,通過構建超大規(guī)模同義詞網(wǎng)絡,為破解這一困局提供了創(chuàng)新方案。這項突破性成果不僅顯著提升了土耳其語AI的語義分析能力,更開創(chuàng)了多語言處理的全新范式。
研究團隊發(fā)現(xiàn),傳統(tǒng)詞匯嵌入技術猶如"色盲"系統(tǒng),雖能感知詞語間的溫度關聯(lián),卻無法區(qū)分"熱"與"溫暖"的同義關系和"熱"與"冷"的反義關系。更棘手的是,當系統(tǒng)嘗試構建大規(guī)模語義網(wǎng)絡時,會出現(xiàn)類似"傳話游戲"的語義漂移現(xiàn)象——"熱"經(jīng)由"辣""疼"等中間詞,最終可能與"抑郁"形成錯誤關聯(lián),導致語義網(wǎng)絡嚴重失真。
為攻克這一難題,科研人員首先開發(fā)出三分類語義識別系統(tǒng)。該系統(tǒng)利用Gemini 2.5-Flash語言模型生成84萬組標注數(shù)據(jù),結合權威詞典的1.6萬組"黃金標準"數(shù)據(jù),通過監(jiān)督學習訓練出高精度分類器。實驗數(shù)據(jù)顯示,該系統(tǒng)識別同義詞準確率達83%,反義詞識別準確率更高達92%,遠超傳統(tǒng)方法的性能表現(xiàn)。
針對語義漂移問題,研究團隊創(chuàng)新設計"軟到硬"兩階段聚類算法。初始階段允許詞語同時歸屬多個語義群組,有效處理"yüz"這類既表示"面部"又表示"數(shù)字100"的多義詞。后續(xù)階段通過智能投票機制,根據(jù)詞語與各群組的關聯(lián)強度進行最終歸類。系統(tǒng)還引入路徑驗證機制,要求兩個詞語必須擁有足夠比例的共同鄰居才能歸入同群,從拓撲結構層面杜絕錯誤連接。
處理1500萬詞匯產生的超5億組潛在關系,對計算能力構成巨大挑戰(zhàn)。研究團隊采用FAISS向量搜索系統(tǒng),運用8位量化技術將60GB數(shù)據(jù)壓縮至15GB,同時保持關鍵語義特征。通過分層索引結構將搜索空間劃分為1.6萬個區(qū)域,使計算復雜度從平方級降至對數(shù)級,最終從13億候選對中篩選出5.2億組有效關系。
嚴格的質量控制體系貫穿研究全程。系統(tǒng)實施雙向驗證機制確保同義關系的對稱性,自動剔除矛盾關系對。在代表詞選擇上,優(yōu)先采用權威詞典術語,其次選取語義距離最近的詞匯,保證每個語義群的典型性。實際測試顯示,系統(tǒng)能準確區(qū)分"yüz"的解剖學與數(shù)學含義,并將OCR識別變體"Mücbir Sebe"等正確歸類到"不可抗力"概念下。
最終構建的同義詞網(wǎng)絡包含290萬個語義群組,覆蓋1500萬土耳其語詞匯。群組規(guī)模呈現(xiàn)合理分布:中位數(shù)3個詞匯,平均4.58個,最大群組含86個相關詞。這種結構既避免過度聚類,又確保語義完整性。實驗表明,針對土耳其語特化訓練的模型,在相同架構下比通用多語言模型性能提升15%,凸顯語言適配訓練的重要性。
該成果已產生顯著應用價值。在搜索引擎場景中,系統(tǒng)能準確識別"法律條文"與"法規(guī)"的同義關系,同時排除"違法行為"等反義概念。對于檢索增強生成系統(tǒng),精確的語義理解可使信息檢索準確率提升30%以上。研究團隊已開放技術接口,只需基礎語言資源即可為其他語言構建同義詞網(wǎng)絡,為資源匱乏語言提供可行解決方案。
這項研究從根本上重構了語義關系處理范式。通過顯式關系分類與拓撲感知聚類的結合,系統(tǒng)在保持大規(guī)模處理能力的同時,將語義理解精度提升至新高度。特別是針對土耳其語等形態(tài)復雜語言,研究展示的LLM增強監(jiān)督學習方法,為處理詞形變化豐富的語言提供了有效路徑。完整技術方案已通過arXiv平臺公開,為全球多語言AI發(fā)展樹立了新的技術標桿。