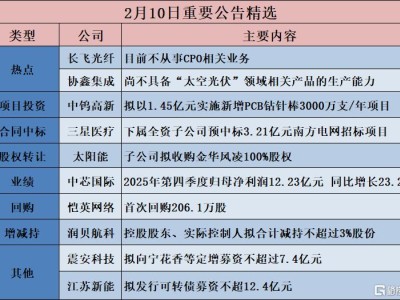
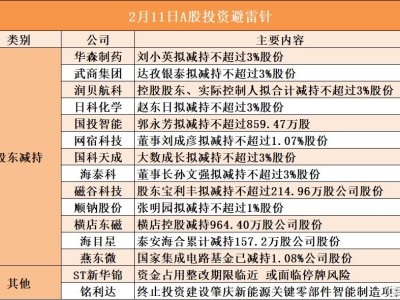
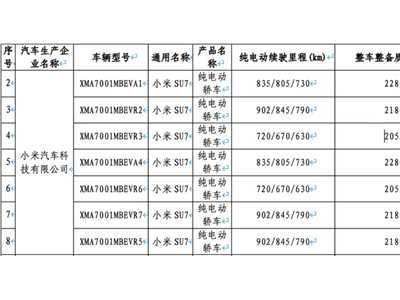
阿里千問團隊近日宣布推出一項名為DeepPlanning的新型AI基準測試,旨在評估智能體在復雜現實場景中的全局規劃能力。該測試突破傳統推理任務的局限,要求AI系統在制定計劃時必須統籌兼顧多個約束條件,而非僅關注局部最優解。
以多日旅行規劃為例,AI需在時間、預算等硬性限制下,精確安排每項活動的時間節點,誤差需控制在分鐘級別。在電商購物場景中,系統要能自動組合商品、疊加優惠券,并動態調整方案以達到滿減條件,實現總價最低。這些約束條件需貫穿整個規劃過程,而非僅在特定步驟滿足要求。
基準測試結果顯示,當前主流大模型在處理復雜規劃任務時仍存在明顯不足。包括GPT-5.2、Claude 4.5、Gemini和Qwen 3在內的頂尖模型,在全局優化和長周期一致性方面表現欠佳,距離實現完全自主決策仍有差距。測試數據表明,這些模型在處理需要多維度權衡的復雜場景時,往往難以保持計劃的整體連貫性。
為推動該領域研究發展,阿里千問團隊已將DeepPlanning基準測試完全開源。研究人員可通過Hugging Face平臺(https://huggingface.co/datasets/Qwen/DeepPlanning)和魔搭社區(https://www.modelscope.cn/datasets/Qwen/DeepPlanning)獲取完整數據集,包含多種復雜規劃場景的測試用例及評估標準。這一舉措將為AI規劃能力的研究提供標準化評估框架,促進相關技術的迭代升級。