全球人工智能領域正經歷一場關于模型發展方向的深度討論。當主流科技公司仍在追逐基準測試高分時,字節跳動推出的豆包2.0模型卻選擇了一條差異化路徑。這款新模型不再單純追求解題能力,而是將核心優化方向轉向處理真實業務場景中的復雜任務,這種轉變引發行業廣泛關注。
企業用戶調研顯示,超過70%的日常需求集中在處理非結構化數據。這類需求往往涉及圖表解析、文檔處理與多步驟專業任務的銜接,而非傳統認知中的數學難題求解。豆包團隊基于這一發現,在模型架構中重點強化了多模態理解、長上下文處理和指令遵循能力,這些被行業視為"非性感但實用"的技術模塊。
在技術實現層面,研發團隊對多模態融合架構進行根本性改造。傳統模型通過簡單拼接視覺編碼器與語言模塊的方式被徹底顛覆,新架構實現了視覺語義與文本信息的深度交互。這種改進使模型能像人類一樣理解圖像中的因果關系,例如通過人物神態和穿著判斷其正在進行的演講活動,而非僅識別畫面中的孤立元素。
注意力機制的優化是另一個技術突破點。面對長文本或視頻處理任務,模型采用動態注意力分配策略,自動識別關鍵信息節點。這種機制模擬人類閱讀習慣,在處理技術文檔時能優先捕捉核心參數,在觀看教學視頻時可聚焦關鍵操作步驟,有效解決了傳統模型在長序列處理中的注意力分散問題。
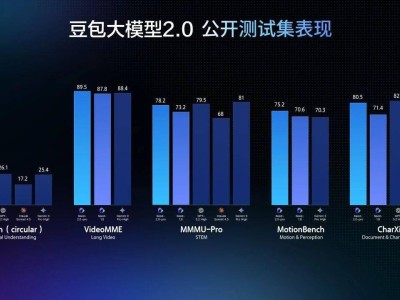
基準測試數據顯示,豆包2.0 Pro在HLE-Text綜合評測中以54.2分領跑群雄,在HealthBench醫療測試中取得57.7分的最佳成績。特別值得注意的是,該模型在EgoTempo時序理解測試中超越人類基準水平,展現出在動作捕捉和節奏分析領域的獨特優勢。這些成績的取得,得益于訓練過程中對推理鏈的顯式建模,使模型具備逐步推導的邏輯能力。
實際應用場景中,豆包2.0展現出強大的任務執行能力。在生物醫學領域,模型能將基因工程實驗設計、小鼠模型構建、多組學分析等跨學科步驟整合成完整方案,其細節處理能力超出專家預期。在編程領域,通過與TRAE平臺的深度集成,開發者僅需5輪提示詞即可完成包含11個AI驅動NPC的互動項目開發,顯著提升原型設計效率。
火山引擎同步上線的API服務,為開發者提供三種規格的通用Agent模型選擇。其中Code模型專門針對編程場景優化,支持流式實時視頻分析功能。在健身指導場景中,模型可實時觀察用戶動作并提供糾正建議;在時尚領域,能根據用戶穿搭視頻即時生成搭配建議,這些應用突破了傳統事后分析的模式限制。
研發團隊坦承,在端到端代碼生成和上下文學習等方面,豆包2.0與國際頂尖模型仍存在差距。這種實事求是的態度,反而為模型后續優化指明方向。相較于追求榜單排名,字節跳動更關注模型在真實業務場景中的落地效果,這種以需求驅動的研發策略,正在重塑人工智能模型的評價標準。