短視頻搜索業(yè)務是向量檢索在工業(yè)界最核心的應用場景之一。然而,當前業(yè)界普遍采用的“自強化”訓練范式過度依賴歷史點擊數(shù)據(jù),導致系統(tǒng)陷入信息繭房,難以召回潛在相關的新鮮內容。針對當前挑戰(zhàn),快手搜索團隊提出了CroPS框架,從根源上打破數(shù)據(jù)閉環(huán)。目前,CroPS已在快手搜索業(yè)務中實現(xiàn)全量部署,服務億級用戶。
本工作相關成果《CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search》已被人工智能頂級會議AAAI 2026 Oral接收。
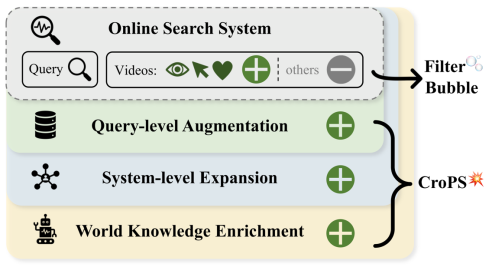
為了打破數(shù)據(jù)邊界,CroPS 框架構建了一個包含三個維度的正樣本增強引擎,分別利用用戶換Query行為、推薦系統(tǒng)反饋以及大語言模型(LLM)的世界知識,來全方位地豐富語義空間。圍繞這一目標,CroPS 分別從查詢行為、系統(tǒng)反饋和外部知識三個層面展開。
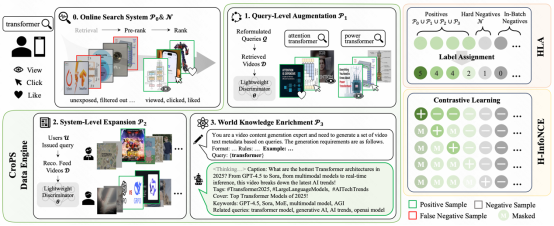
在真實的搜索場景中,用戶往往難以一次性精準表達意圖。當用戶輸入查詢詞A 卻未能找到滿意結果時,通常會進行查詢重構,輸入語義相關但表述不同的查詢詞B。CroPS 通過分析用戶在短時間窗口內的改寫序列,將改寫后獲得的成功點擊回流給原始查詢,利用用戶的修正行為來糾正模型的語義偏差。
推薦系統(tǒng)擁有海量用戶消費數(shù)據(jù),其算法機制天然傾向于發(fā)散和探索。CroPS 建立了一套跨系統(tǒng)的信號橋接機制:對于同一個用戶,如果他在推薦信息流中深度消費了某個視頻,且該視頻在語義上與用戶近期的搜索詞高度相關,該視頻就會被引入作為搜索模型的正樣本。
當平臺現(xiàn)有的內容庫或日志無法覆蓋某些長尾、復雜查詢時,CroPS 引入大語言模型(LLM)作為虛擬檢索器和內容生成器,利用 One-shot Prompting 策略生成高質量合成樣本,將外部世界的常識與邏輯蒸餾進檢索模型中。
在多源正樣本被引入之后,如何讓模型有效利用這些信號,同樣成為訓練階段的關鍵。HLA 的核心是解決 CroPS 多源正樣本的可靠性差異問題,通過為樣本分配分層標簽,讓模型能夠學習更細粒度的相關性。H-InfoNCE 在訓練時,將當前樣本與標簽嚴格低于它的所有樣本進行對比,使學習目標與 HLA 的層級邏輯完全對齊。
這一系列設計共同構成了 CroPS 在工業(yè)檢索場景中的完整解決方案。CroPS 證明了在工業(yè)檢索系統(tǒng)中,正樣本增強是緩解信息繭房問題的有效鑰匙。未來,快手搜索團隊將進一步探索 CroPS 與生成式檢索(Generative Retrieval)方法的融合,持續(xù)挖掘大規(guī)模語言模型在搜索全鏈路中的潛力。