在人工智能領(lǐng)域,原生語音推理模型的競(jìng)爭(zhēng)愈發(fā)激烈。近日,全球知名的大模型評(píng)測(cè)榜單Artificial Analysis Speech Reasoning迎來更新,階躍星辰推出的原生語音推理模型Step-Audio-R1.1憑借卓越表現(xiàn)登頂榜首,引發(fā)行業(yè)廣泛關(guān)注。
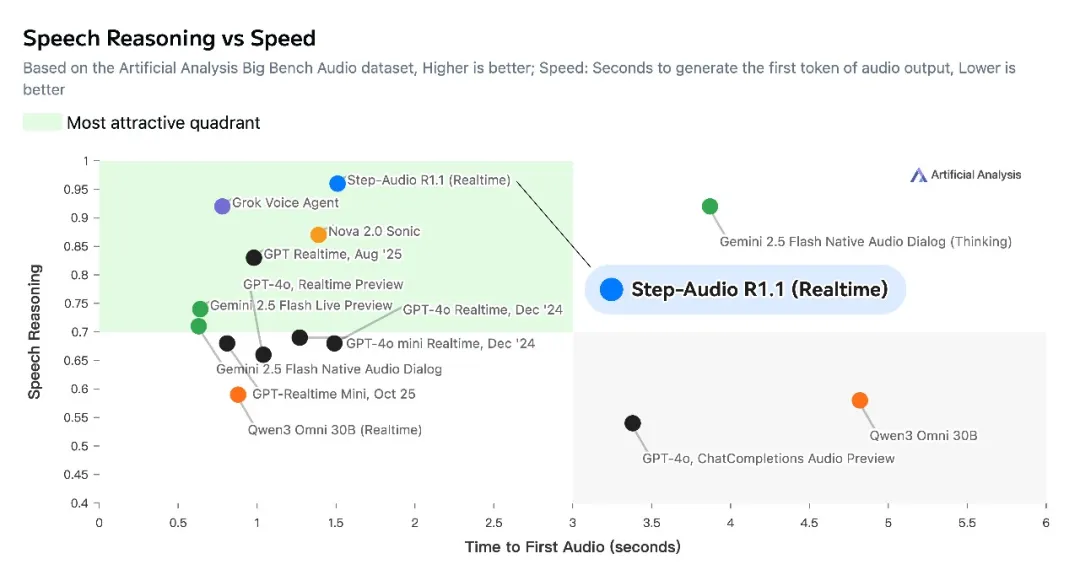
Artificial Analysis Speech Reasoning榜單作為評(píng)估“原生語音模型”的權(quán)威第三方基準(zhǔn),重點(diǎn)考察模型直接處理音頻并完成復(fù)雜邏輯推理的能力,準(zhǔn)確率、首包延遲等關(guān)鍵指標(biāo)是衡量模型性能的重要維度。在這樣嚴(yán)格的評(píng)判標(biāo)準(zhǔn)下,Step-Audio-R1.1脫穎而出,以96.4%的準(zhǔn)確率超越了Grok、Gemini、GPT-Realtime等主流一線模型,刷新了該榜單的歷史最好成績(jī)。
語音模型若要實(shí)現(xiàn)更高階的智能交互,強(qiáng)大的推理能力必不可少。如同大語言模型需要深度理解語義并給出合理回應(yīng)一樣,語音模型也需具備類似能力,才能讓用戶感受到自然流暢的交流體驗(yàn)。Step-Audio-R1.1在性能與速度的綜合權(quán)衡上表現(xiàn)突出,全面碾壓同類語音模型。它由階躍星辰發(fā)布,其前代Step-Audio-R1是全球首個(gè)開源的原生語音推理模型,能夠在不增加額外時(shí)延的情況下,端到端地理解語音內(nèi)容,實(shí)現(xiàn)“像人類一樣聽到對(duì)話即可思考”的效果。
Step-Audio-R1.1作為最新升級(jí)版本,在繼承前代優(yōu)勢(shì)的基礎(chǔ)上,進(jìn)一步提升了實(shí)時(shí)對(duì)話和復(fù)雜語音推理能力。其核心能力涵蓋深度語音推理、實(shí)時(shí)響應(yīng)能力以及音頻領(lǐng)域的可擴(kuò)展CoT。這些能力使得該模型在處理語音任務(wù)時(shí)更加高效、精準(zhǔn),能夠滿足多樣化的應(yīng)用場(chǎng)景需求。
目前,Step-Audio-R1.1的權(quán)重已上傳至HuggingFace,方便開發(fā)者進(jìn)行研究和應(yīng)用。同時(shí),開放的chat模式已搭載R1.1核心,支持邊想邊說的流式推理,為用戶帶來更加流暢的交互體驗(yàn)。完整的實(shí)時(shí)語音API預(yù)計(jì)將于2月上線,屆時(shí)將進(jìn)一步拓展該模型的應(yīng)用范圍,推動(dòng)原生語音推理技術(shù)在更多領(lǐng)域的落地。